
Overview
The word "DevOps" is the coalescence of two terms "Development" and "Operations". Today, a majority of the people have a perplexity on the DevOps concept whether it is a culture, movement, approach, or a blend of all these things. Here in this DevOps Tutorial, we have got you covered with all your crux over the DevOps concepts in sequential order. This DevOps Tutorial helps you to have a fair understanding of the DevOps concepts, tools, technologies, and other important approaches that are associated with it.
Intended Audience: This DevOps Tutorial series is compiled with the intent to make beginners familiar with DevOps Concepts who aspire to head-start their career in the IT domain.
Prerequisites: There are no requisites needed for learning the DevOps concepts as this DevOps tutorial for beginnersguides you right from the basics. Yet, it is advisable to have a prior understanding of the Linux and Scripting fundamentals.
What is DevOps?
Today a predominant of IT companies have deployed the DevOps as a way to forward in the march of competition that is prevalent in the market. Here in this DevOps Tutorial for Beginners first let understand What is DevOps?
The term DevOps is the blend of two words "Development" and "Operations" This is the kind of practice that permits a single team to handle the complete application of the development cycle namely development, testing, monitoring, and deployment. Eventually, DevOps aims to reduce the development life cycle whilst rendering the features, updates, and fixes in harmony with the business goals and objectives.
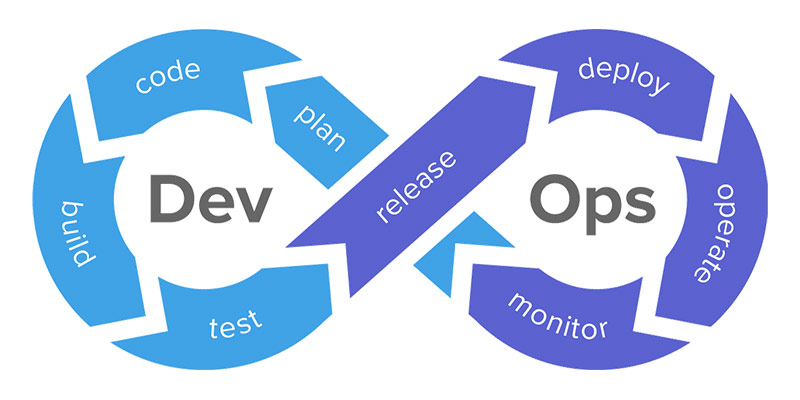
Adopting the DevOps culture alongside its tools and practices, the organizations shall be able to respond to their customer's requirements at ease and shall boost the performance of the application significantly, and thus support reaching the business goals at a rapid pace. A DevOps consists of different stages and they are -
- Continuous Deployment
- Continuous Integration
- Continuous Testing
- Continuous Deployment
- Continuous Monitoring
Needs to Learn DevOps
DevOps is the method of Software development where the development and the operation team collaborates at every stage of the software development cycle. Below in this DevOps Tutorial for Beginners, we have enlisted the important needs to learn DevOps,
- It has made innovative and remarkable changes in the practice of Software Development. The complete team takes part in the development process and it aims for the common goal.
- When there is continuous integration, then there is a consequent reduction in the manual processes that are involved in the development and testing stages.
- It accelerates the chances to work with efficient team members where the knowledge sharing would be significantly higher and helps to have a cordial relationship among the team members.
- Last but not the least, with never-ending changes in the IT industry, the demand for skilled DevOps professionals is expected to increase tremendously.
History of DevOps
Having seen what DevOps is and the need to learn DevOps. In this DevOps Tutorial, we will guide you deep into the Core of DevOps and how it came into the scenes in the industry. Before introducing the DevOps the Software Development industry had two main approaches and they are - Waterfall and Agile model of development.
Waterfall Model
- This is the kind of Software Development model which is direct and linear. The Waterfall Model follows the approach of the top-down method.
- Also, this model has different starting with the requirement analysis and gatherings. This is the stage where you gather all the requirements from the clients to develop the application.
- The next stage is the Designing stage where you are required to prepare the Blueprint for the software. Here, you can sketch out the designs as how your software is going to look like.
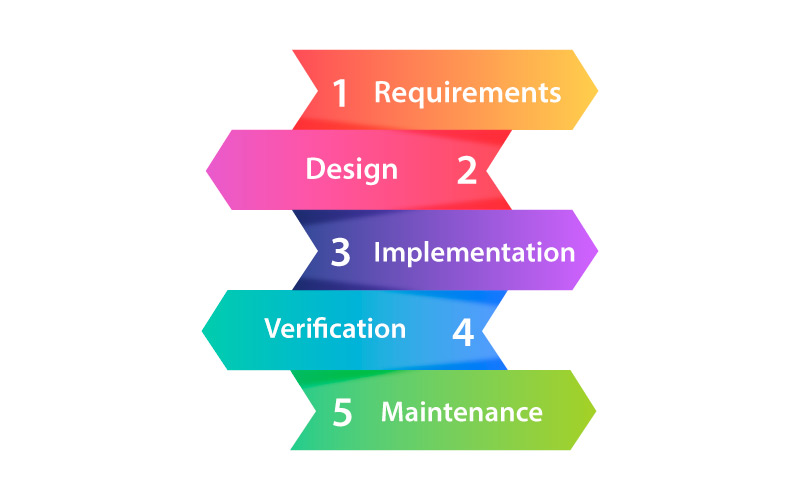
- Once when the designs are done, they can further be mapped to the Implementation phase, where the coding for the application starts. And here, the team of developers coordinates and works together on different components of an application.
- In case if you are done with the application development process, then now you are required to test the developed application in the verification stage. There are different tests conducted on the applications namely integration testing, unit testing, and performance testing.
- Once when you are done with all the test processes of the application, then they are deployed in the production servers.
- Finally, comes the Maintenance stage, here in this stage the application is scrutinized to ensure its performance. Also, any issues that are associated with the performance of an application are dealt with in this phase.
Upsides of the Waterfall Model
- It is simple and easy for understanding and using it
- It allows performing analysis and testing
- It saves maximum time and money
- This is mainly preferable for smaller projects
- The Waterfall model allows the access of Managerial and Departmentalization of control
Downsides of Waterfall Model
- It is highly uncertain and risky
- There is a lack of visibility on the current progression
- It is not preferable when the requirements constantly modify
- It is strenuous to make changes in the products when they are in the testing phase
- You can find the end product only after the complete end of the cycle
- It is not recommended for complex and larger products
Agile Methodology
It is an iteratively based software development approach where the software project is broken into different sprints and iterations. All the iteration consists of the phases that are found in the waterfall model namely - gathering, requirements, designs, testing, development, and maintenance. The total span of every iteration is 2-8 weeks.
Process of the Agile Model
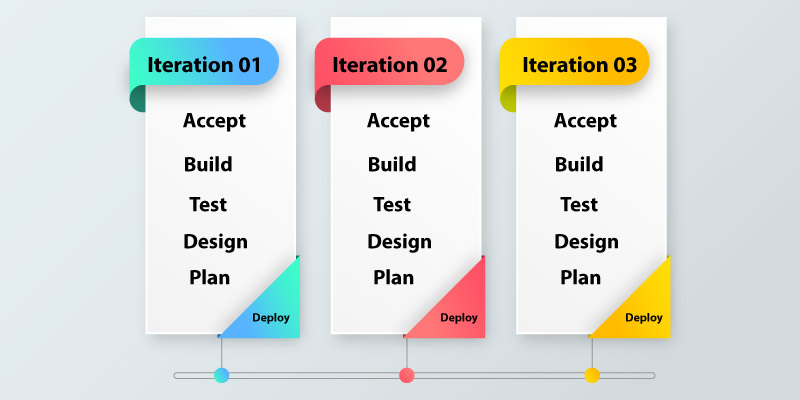
- The Agile company launches the application with high-priority features in its first iteration.
- Once the release is over, the customers or the end-users provide feedback on the performance of an application
- Also, we can make the required changes that are found in the application with features and applications that are launched again with the second edition
- You could repeat the complete process until you have reached the specific software quality
Upsides of the Agile Model
- This response to the needs and changes more adaptively and suitably
- Also, fixing the errors at the early phase of development helps the process to be more cost-efficient
- It enhances the quality of the product and thus makes them error-free
- It permits direct communication among the people who are involved in the Software Development project
- It is highly recommended for the big and long-term projects
- Also, the Agile model needs only minimum resources and this is very easy to handle
Downsides of the Agile Model
- It is highly dependent on the customer needs
- It is not easier to predict the effort and time of the bigger projects
- It is not preferable for complex projects
- It struggles more with the document efficiency
- It helps in maintaining the risks
Even though with the advancing Agile methodology, the Operations and Development teams in an organization remained siloed for many years. And here came DevOps, the next big transformation of collaboration of practices and tools for releasing better software at a faster pace. Initially, the DevOps movement began between 2007-2008. During that time the Software Development and IT Operation team strongly felt that there was a catastrophic level of dysfunction in the industry. Also, they fumed the traditional method of Software development model as the coders and as well as testers were functionally and organizationally different.
Furthermore, the Developers and the Operating professionals in the past had a separate department, leadership, objectives, goal, performance methods, and they were assessed on a different basis. Often these professionals were under different roofs or buildings. Also, the results were siloed to the specific teams. However, DevOps has the flexibility of reaching every stage of both the Development and Operation lifecycle. Right from planning to building and monitoring to iterating, DevOps get in together the processes, skills, and tools for every phase of development and operation process in the IT organization.
The DevOps entrust the team to test, build, and deploy at a faster pace with supreme quality. It is possibly achieved owing to the tools that are offered by it and this DevOps culture immensely blended with the Corporate culture and ideology which will help the organizations to move further. The true power of DevOps could be reached only when there is good communication and understanding between the team members for reaching the shared goals. The DevOps Training in Chennai at FITA Academy helps the students of the program to have a holistic understanding of the DevOps concepts and its tool under the mentorship of real-time professionals.
Applications of DevOps
DevOps is not only used by the developers and operators. Rather this is used by the administrators such as project managers, test engineers, and in the different segments by the administrators. There are numerous practices that permit the organization to offer faster and more reliable updates for its customers. The DevOps core aspect revolves around the Agile principle, which is the significant influencer of DevOps concept creation. Below we have listed down the applications,
Microservices: It is a well-planned approach that supports building single apps as a package for small services. All the services in these applications are capable of communicating through well-defined interfaces. It utilizes the lightweight mechanism which is mostly the HTTP-oriented API.
Infrastructure as Code: This is the practice on which the Software Development codes and techniques are built and the infrastructure is handled. Usually, the developers and system administrators shall communicate through the API-driven models of the Cloud. Rather than configuring and setting up them manually, the IaC communicates with the infrastructure programmatically.
Monitor and Logging: Mostly the enterprises inspect the logs and metrics to check the roots and the application's performance to measure the end-user experience. Also, active monitoring is crucial to ensure that the services are there 24/7 without any interruptions.
Continuous Integration: It constantly indicates the repeated testing and merging. Continuous integration intends to identify the bugs and defects at an earlier stage to enhance performance. Also, it significantly reduces the time that is taken for validating and releasing the updates on the software.
Collaboration and Communication: One of the prime goals of DevOps is to promote better collaboration and communication. The automation and tooling of the software render the process by bringing in the workforce under one roof of operation and development. It helps in boosting the communication among the departments. Also, teamwork permits the potent accomplishment of any assigned tasks. Enrolling in a DevOps Course in Trichy can help professionals understand how these practices enhance collaboration and streamline workflows effectively.
DevOps in Networking: The doctrine of the DevOps concept is alluring and it is harvesting unprecedented popularity in handling Networking services. With the aid of the vendor hardware, deployment modes, automation of the network functions, devices, and configuration tools it has just become an easier job for the professionals to deploy it.
DevOps in Data Science: The companies are persistently working hard to become more buoyant. And thus more organizations are switching to DevOps to deploy the codes robustly and efficiently. And it makes use of the integrated method and successively deploys the plan of the Data Science in the production. Also, it uses the perfect direction for robust implementations.
DevOps in Testing: Based on a survey report gathered from the RightScale, it is stated that numerous companies have preferred DevOps for testing. It is done for reaching agility and speed as it is more essential to automate the complete process of the configuration and testing. The complete function of DevOps is entrusted on the "Agile Manifesto". And yet the root of the proficient strategy is called the "DevOps Trinity" and it is:
People and Culture: When you adopt DevOps, it helps in eliminating all the differences among the teams. Also, they mainly work on a common goal. The main purpose of DevOps is to gain quality software.
Tools and Technologies: DevOps is one of the sustainable and adaptable models with a range of technology and tools. It allows the complete process of the operation and development to be a much easier one.
Processes and Practices: Both the DevOps and the Agile go together. Thus, on the deployment of Agile, Scrum, Kanban, or Plus automation the organizations were able to streamline the processes in a replay.
DevOps Architecture
In the arena of Software Engineering, both the Development and the Operation team occupy a vital role in application delivery. Generally, the Development team constitutes the administrative services, processes, and support of the software. When both the Development and the Operation teams are joined together for collaborating, the DevOps architecture comes into play. The DevOps concept is the only way to bridge the gap between the Development and Operation teams so that the delivery of the software could be achieved rapidly with lesser issues. Here in this DevOps Tutorial for Beginners, we will dive deep into the components of the DevOps architecture.
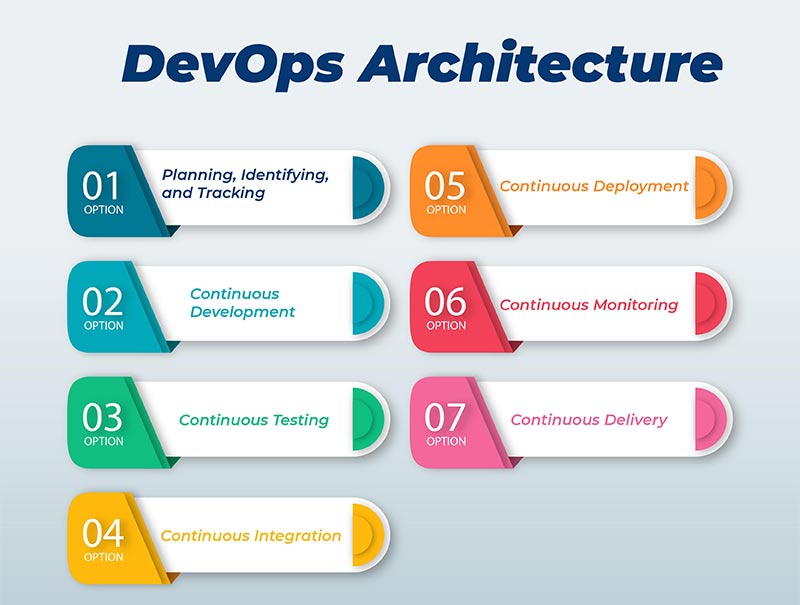
Generally, the DevOps Architecture is used for hosting the largely distributed applications on the Cloud platform. And the DevOps allows the team to alter their shortcomings flexibly and enhances productivity immensely. Below are the important components of the DevOps and they are;
Planning, Identifying, and Tracking: Upon using the recent project management tools and practices, help the team to track the ideas and the workflows more visually. By doing this the Stakeholders could easily get an overview of the progress and also they could easily alter prioritization to achieve better results. When there is better oversight the Project Managers could ensure that the team is operating on the right track and that they are aware of the near pitfalls and obstacles. Further, the teams could operate together to resolve any issues that are found in the development process.
Continuous Development: The Developers in the initial stage plan, build and execute the code on a different version of the control system namely Git which holds the source code. Also, after the final release, there may be feedback or suggestions which a developer should incorporate into the application. Hence, the continuous process of enhancing the application by the Developer is termed "Continuous Development".
Continuous Testing: Once the code is uploaded into the Source code platform it undergoes the testing phase. Here in this phase, every time the codes are tested and the necessary changes are implemented on those codes before pushing them to the production team.
Continuous Integration: When you complete one stage of the DevOps lifecycle, the application code should be moved immediately to the next stage. This could take place with the aid of the integration tool. The Development practice persistently harmonizes the code right from the first stage to the next level with the support of tools and they are called continuous integration.
Continuous Deployment: After the addition of every feature on the application, it would need a few modifications to the application environment. It is called Configuration Management. To attain this, we should make use of more deployment tools. The process of continuous change on the application environment based on the recent addition of the attribute is termed Continuous Deployment.
Continuous Monitoring: After every testing and planning the bugs may identify their means to the production. We could keep track of those bugs or other inappropriate system behavior. Also, we could keep track of the feature request and monitor the tool persistently to check when and how the application goes through the updates.
Continuous Delivery: Last, but not least, the DevOps architecture is developed on the motto of Continuous Delivery. This means that any practice that is set on the play shall foster collaboration and communication among the teams and it should function toward the constant and routine delivery of the tested software. It could be automated just like continuous deployment as mentioned above. Learners can gain a deeper understanding of these principles and automation techniques by enrolling in a DevOps Training in Erode.
Advantages of DevOps Architecture
The properly implemented DevOps approach comes with more benefits. It includes the following and they are
Cost Reduction: One of the primary concerns for any business would be the operational cost. The DevOps aids the organizations to keep their cost or expenses at a lower range. Owing to efficiency it gets the boost with the DevOps practice and the Software production enhances the business performance to foresee the overall decrease in the cost of production.
Improved Productivity and Release Time: With the curtailed streamlined processes and development cycles, the teams become more productive and the software is deployed robustly.
Efficient and Time-Saving: The DevOps eases the lifecycle with the earlier iterations that have been growing complex over time. However, with DevOps, the organizations could gather all the requirements at ease. The thing to be noted here is that, in the DevOps, the process of collecting the requirements is streamlined and a culture of collaboration, accountability, transparency meets the requirements in a smooth sail with team efforts. And with this practice, an organization could achieve anything.
Customer Satisfaction: The User Experience and the User feedback is the most important accept of the DevOps culture. By collecting all the details from the clients and then acting based on it helps to ensure that the client's requirements and needs are fulfilled completely to reach new heights in achievements.
Principles and Workflow of DevOps
DevOps was earlier called the mindset and the culture which strongly withholds the collaborative bond among the infrastructure operations and the software development teams. This culture is fundamentally built on the below principles
Gradual Changes: The utilization of the gradual rollouts permits the delivery teams to release the product of the users to have the opportunity to use the updates and the rollbacks when something goes wrong.
Constant Communication and Collaboration: This is the building block of the DevOps concepts ever since its inception. Both the Operation and Development teams should function cohesively and collaboratively to comprehend the requirements and expectations of all the members of the organization.
Sharing of end-to-end Responsibility: All the members of the team should march towards one specific goal and this is responsible equally for a project right from the very beginning till the end that is to facilitate and aid with the need of other member's tasks.
Ease of Problem-solving: DevOps would require the tasks that have to be performed in the early stage of the project lifecycle. So, DevOps mostly concentrate on the tasks of these types and lays the efforts to address these issues more quickly.
Measuring KPIs (Key Performance Indicator): Usually, the Decision-making process must be powered with the factual information in the first stance. It is important to keep track of the progress and activities that make up the DevOps workflow in order to achieve optimum efficiency. To measure the different metrics of the system you should first allow the system to have an understanding of which goes well with the system and what else could be done to enhance the performance.
Automation of Processes: The golden rule of DevOps is to automate as many things as possible like testings, configurations, deployment procedures, and developments. It permits the Specialists to overcome the time-consuming and repetitive work and thus to focus on the other essential activities that could not be automated by nature.
Sharing: The DevOps philosophy in actual highlights the common English phrase "Sharing is Caring''. The DevOps culture highlights nothing but the significance of the collaboration. It is a crucial aspect of any work to share feedback. We can also say that it is one of the best practices to widen your knowledge and skills among your teams and this eventually promotes transparency that develops more collective intelligence and excludes constraints significantly. Also, on adopting the DevOps process, you need not just stop a development process just because only a single person could handle the task efficiently and that person is out of work due to some reasons.
The DevOps Online Training at FITA Academy enables a comprehensive view of the DevOps concepts like - Continuous Integration, Continuous Deployment, Continuous Testing, and Continuous Monitoring under the leading DevOps Experts from the industry. By the end of the training program, the students would acquire a clear understanding of the DevOps concepts.
DevOps Process

Plan: It is the part of the development process where you would organize the schedules, tasks, and setting up of your project management tools. The primary idea is to plan the tasks by using the user story of the process right from the agile methodology. We can also write the tickets in the method of user store for permitting the Operational engineers and Developers to comprehend the development requirements and why it is done.
Code: In this stage, the developer performs coding and reviews the code completely. When the code is ready you can merge them easily. Also, in the DevOps practice is it more important to share the code among the Developer and the Operating engineers.
Build: It is the first where one moves towards automation. The aim here is to build the source code in one desired format, testing, compiling, deploying in the specific place of an infrastructure. Once the setup is done then CI and CD tools could be verified with the support of the Source Code Management and build them.
Test: On performing the Continuous testing process, the organization could easily reduce the risk. The Automatic test makes sure that there are no bugs that are implemented in the production stage. We can implement those testing tools in the workflow to ensure that the best development of quality software is produced.
Release: Every code has to be passed in the testing process only then it is considered to be ready for deployment.
Deploy: The Operational Team deploys the new feature on the production. However, automation is one of the major principles of DevOps and this is possible only to set up with continuous deployment.
Configure/Operate Infrastructure: The Operation team develops or maintains the scalable infrastructure and the infrastructure as code to evaluate the log management and security control issues.
Monitor: This is the most important step in the DevOps that permits fixing all the incidents which have issues at a faster pace. This eventually enables the users to have a better user- experience.
Since DevOps aims to improve the satisfaction level of your customers, the team could naturally begin the steps over and over with the addition of a new feature on your software or application. This is the major reason why DevOps is considered the endless loop of automation.
DevOps Automation
Today, Automation is the key factor that occupies an important role in DevOps. The question here is how you can in reality place the automation in the practice to advance your goals in DevOps. Here in this DevOps Tutorial session, we have explained in-depth what automation indicates here and the context of automation in DevOps, and the different practices that could be automated to reach the DevOps Automation.
With the never-ending evolution in the technology field, Software Development teams are always under pressure to cope with the growing demand and customer expectation of the business applications. The general expectations are:
- Enhanced Performance
- Extended functionality
- Offer guaranteed uptime and availability
Also, all the Traditional Software Development processes have shifted themselves with the cloud-based applications with the advent of technology. The present paradigm is focused more on developing the software more as an ongoing service instead of creating them simply for specific customer requirements. Software development has come a long way from monolithic to agile structure, where it is possible to develop the software constantly.
Automation
In DevOps, the term automation means getting rid of the need of human engineers for intruding physically to facilitate DevOps practices. In the conceptual aspect, we could perform the DevOps processes namely Continuous Integration(CI), Continuous Delivery(CD), and log in the analytics manually. In doing so you may need a bigger team, a huge time, and a high level of coordination and interaction among the team members that are more relevant to the situation prevailing in the organization. However, with automation, you could perform all these processes by using a predefined set of tools and configurations.
What is DevOps Automation?
DevOps Automation is the method of automating the repetitive and mundane DevOps tasks that could be executed without any intervention on humans. The Automation could be practiced in the entire wheel of the DevOps lifecycle and they are
- Software Deployment & Release
- Design & Development
- Monitoring
The main intent of DevOps Automation is to standardize the DevOps cycle by reducing the manual workload. Thus, the automation results in more key improvements,
- Enhances the Team Productivity
- Reducing Human Errors immensely
- Eliminating the requirement for large teams
- Build a fast-moving DevOps lifecycle
Also, it is important to note here that Automation in DevOps is not completely removing human intervention from the picture. Since there are possibilities where you may build the best-automated DevOps process, however, you may need human intervention or oversight to do the things when there is an update or if there is a bug in the process. Automation can only reduce the dependency of humans to handle the basic or recurring tasks in concern with the DevOps practices.
Advantages of Automation in DevOps
The Automation renders an array of benefits that helps to reach the goal of the DevOps at ease.
Consistency
Usually, the processes are highly automated and are persistently predictable. The Software Automation tool would always perform a similar thing until they are configured again to do the same thing. However, this is not applicable in case if a human is working there.
Scalability
Generally, Automation is considered to be the mother of scalability. Also, these processes are more flexible to handle numerous processes when compared to the manual way of scalability. To brief, consider the instance when you are working manually, you will be able to deploy the new releases only when you are dealing with one specific application or environment. However, when your team handles different applications and that the application is being deployed to a different environment that is more than one Cloud or OS, you can release the newer codes rapidly and consistently.
Speed
The automation here means the processes such as Code Integration and thus the Application deployment occurs at a rapid pace. To adhere to the above statement let us consider some scenarios. When you have automation deployed, you may not wait for the required person to process it, you can just simply deploy the new release or update irrespective of the time and dependency of a person. With the aid of automation tools, you could easily overcome the delay factor.
Secondly, with the in-built automated processes, you could execute the assigned work more rapidly. Over here when you have an Engineer employed, the Engineers should imply some of the criteria like checking the environment, typing out the configuration, and physically checking whether the latest version was deployed successfully. In contradiction, the automation tool could perform the operations more instantly.
The Things to be Prioritized for the DevOps Automation
Many processes and practices are found in the DevOps and it shall differ from one enterprise to the other. Here in this DevOps tutorial, we have jotted down some of the common processes that could be prioritized for the automation process.
Software Testing: In the testing process, before releasing the Software it has to undergo some testing process. However, when you perform this manually you would need more time and workforce. You can overcome this obstacle with the aid of automation test tools like Appium and Selenium With these tools, the Software Testing process is way easier and the test could be performed in a proper routine.
CI/CD: Rapid application development and delivery is the core or central theme of the DevOps concept. Also, it is much more difficult to reach the goal when you don't automate the CI - Continuous Integration, CD - Continuous Delivery process.
Monitoring: There is one major hindrance in the DevOps environment is that to keep the track of all the components in the rapidly moving environment. The automation tools could be used for checking the performance, availability, and security issues that generate the alerts based on the ability to resolve an issue.
Log Management: The total amount of the log data is developed by the DevOps environment and that it is more widespread. The process of gathering and analyzing every data by hand is not possible for many teams. Rather, we can rely on the log management solution which could robustly cumulate and analyze the log data.
The Popular DevOps Automation tools
In the case of automation, more software options are available. Both the open-source and the licensed tools support the complete automation of the DevOps pipeline. Among them, the most widely used type is the CI/CD tools.
The Chef and Puppet are used for cross-platform configuration management. These tools primarily handle the deployment, configuration, infrastructure management, automation, and management of the infrastructure.
TeamCity, Jenkins, and Bamboo are the popular CI/CD software that automates the tasks right from the beginning of the pipeline till the deployment stage. Apart from this, there are specialized tools and software that aims at a single function and this is the most crucial aspect of the DevOps pipeline
Infrastructure Provisioning: Terraform, Vagrant, Ansible
Containerized Applications: Docker, Kubernetes
Source code management: CVS, Subversion, and Git
Application/ Infrastructure Monitoring: QuerySurge, and Nagios
Security Monitoring: Splunk, Suricata, Snort
Log Management: Datadog, SolarWinds Log Analyzer, and Splunk
Also, it is possible to merge all these tools for building an all-inclusive and automated DevOps cycle.
The other major trend on migrating to the Automation and DevOps tasks is that the Cloud platform shall leverage all the power on the Cloud platform. The two important & major leaders are AWS and Azure. Both these platforms enable their users with a complete set of the DevOps services and that shall cover the entire prospects of the DevOps cycle.
Amazon Web Services: AWS CodeBuild, AWS CodePipeline, AWS CodeStar, and AWS CodeDeploy
Microsoft Azure: Azure Repos, Azure Pipelines, Azure Test Plans, Azure Boards, and Azure Artifacts.
To conclude, Automation is not only about replacing human interactions. Rather it is about thinking that automation is the tool that facilitates efficient workflow in the DevOps cycle. The automation should be primarily focusing on the processes and tasks that would provide more improvement in efficiency or performance. Further, the automation that is merged with the good DevOps workflow would lead to high-quality software with more frequent releases and increased customer retention. The DevOps Training in Coimbatore at FITA Academy imparts the students of the training course with hands-on training practices of the DevOps concepts and its tools proficiently.
Git
Here in this DevOps Tutorial, we are going to see about the Git tool application, lifecycle, and its workflow in-depth.
Git is a distributed source code management and revision control system with a focus on speed. Linus Torvalds created and built Git primarily for the Linux kernel development. It is free software distributed under the GNU General Public License Version 2 (GPLv2). The Git tool aids the developers to have a track of their history and their code files by storing them on the different versions and the server repository which is GitHub. The Git encompasses the attributes of performance, security, functionality, flexibility, and security which the predominant of the individual developers and development team would require.

Features of Git
Open Source: It is an open-source tool and it is released under the label of the General Public License (GPL)
Scalable: Git is a scalable tool and it indicates that the total number of users shall increase and Git could manage any situation easily.
Security: It is one of the most secure tools to use. It makes use of the SHA1 (Secure Hash Function) for naming and finding the objects within their repository. All the commits and files are checked and it is retrieved by the checksum during the checkout. Also, it stacks its history in the manner that the ID of a specific commit relies on the entire development history and it paves the way up to the specific commit. If at all it is published once you can bring it back to its older version.
Speed: The Git tool is so fast that it is capable of accomplishing all the tasks that have been assigned in a specific time. In general, a large number of Git operations are performed mainly in the local repository and it offers more speed to its users. It also offers a centralized version control system that constantly communicates with the server at some place or the other. According to the Performance tests that are conducted by Mozilla it was stated that Git was extremely fast in its application when compared with other Version Control Systems.
Also, it is mentioned that the fetching of the version history from the locally saved repository was way faster than getting it from the remote server. Also, the thing to be noted here is that the foundation of Git is written in the C and C++ language primarily ignores the runtime overheads that are related to the other high-level languages. Since Git was developed with the motto to work majorly on the Linux kernel, hence this is capable of managing large repositories efficiently. Right from the speed to the performance the Git has outperformed its competitors well.
Distributed: One of the important features of Git is it is distributed. The term distributed here means rather than switching the specific project to other machines we shall create the "clone" for the complete repository. Further, instead of having just one central repository, you can just send the changes to all the users who have their repository that is stacked in the commit history of a project. Also, you can not connect to the remote repository for change. The change is just stacked in the local repository whenever it is needed you could push those changes to the remote repository.
Supports Non-Linear Development: The Git supports uninterrupted merging and branching. It supports navigating and visualizing non-linear development. The branch of the Git depicts the single commit. Also, we could construct the complete branch structure with the support of the parental commit.
Branching and Merging: These are the prime features of Git and this makes it look more different from other SCM tools. The Git permits the creation of multiple branches and thus it does not affect each other. We can also perform the task such as creation, merging, and deletion on the branches. Also, it only takes a few seconds to perform this. Some of the important factors that could be achieved using the Branching are,
- You can create a separate branch for the new module of a project commit and you can delete them whenever you need them
- Also, you can have the production branch that always does what it shall get in the production and that it could be merged for testing the branch
- You can also build the demo branch for checking and experimenting with its functioning. Also, it could be removed whenever it is required
- The main benefit of branching is that we can push something to the remote repository and we are not required to pull all the branches into it. Also, you can choose some of the branches or all together.
Staging Area: This area is the unique functionality of Git. It could be contemplated as the preview of the next commit and further the intermediate area where the commits could be reviewed and formatted before completing them. When you make the commit, Git modifies the changes that are on the staging area and further makes them as the new commit.
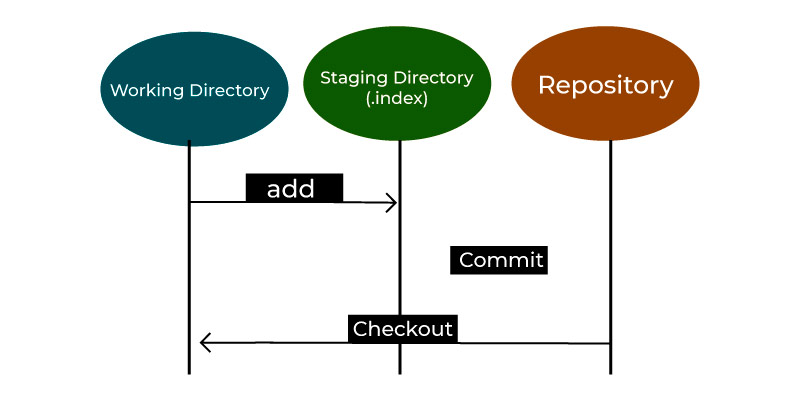
Further, we are permitted to remove and add the changes right from the staging area. The staging area is treated to be the place where the Git shall stack the changes. Though Git does not have any specific staging directory you can stack some of them to the objects that depict the file changes. Over here, Git uses the file which is called index.
Data Assurance: The Git Data model ensures the cryptographic integrity of all the units in the project. It offers the unique commit ID for all the commits via the SHA algorithm. Also, you update and retrieve those commits by the commit ID. Also, the large number of the Centralized Version Control system shall not offer any integrity by default.
Preserves a clean History: The Git promotes the Git Rebase. It is the most important feature of Git. Also, it allows you to get the recent commits from the master branch and then place your code on the top. Git maintains the neat history of your project.
Benefits of Git Version Control
Here in this DevOps tools tutorial, we have enlisted some of the important benefits of Git Version Control.
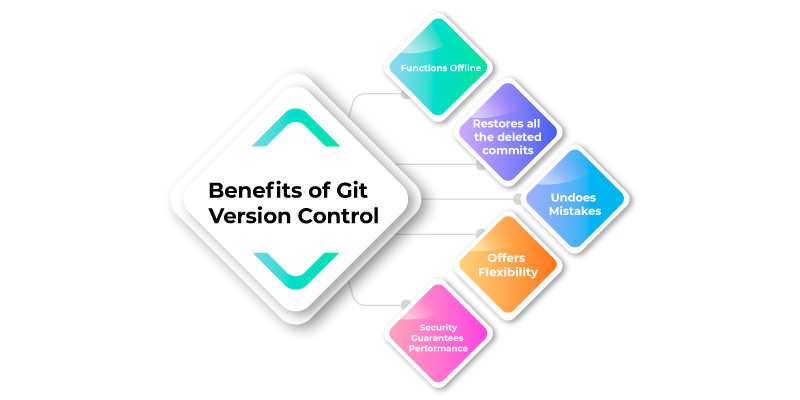
Functions Offline: Git offers its users the most convenient options like permitting them to work both on the online and offline mode. With the other version control system like the CVS or the SVN, the users may not have to access the Internet to connect to the central repository.
Restores all the deleted commits: This feature is useful while dealing with important projects and when you are trying some of the experimental changes.
Undoes mistakes: Git permits you to undo your commands in every situation. You can correct the last commit for small changes and you can revert the complete commit for the unnecessary changes.
Offers flexibility: Git supports its users with various Nonlinear development workflows for all the small and large scale projects
Security: Git offers protection over all the secret alteration of any file and its aids to maintain the authentic content of the history of a source file.
Guarantees Performance: Since its a distributed version control system it provides an optimized performance owing to its features namely merging, branching, committing to new changes, and comparing the older versions of a source file.
Lifecycle of Git
Here in this DevOps tools tutorial let us see in-depth about the lifecycle of the Git tool
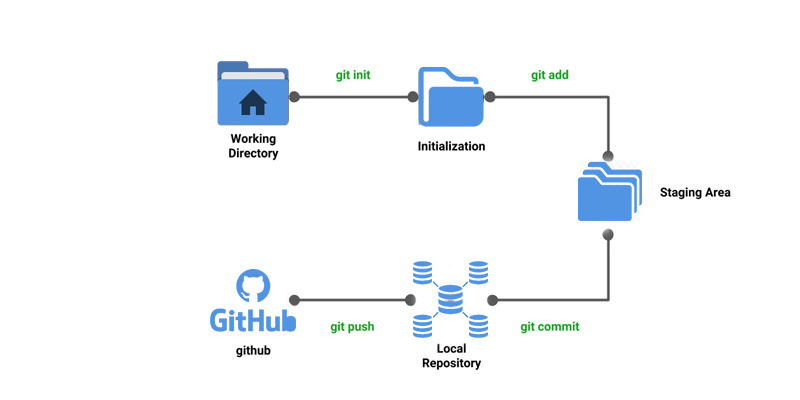
Local Working Directory: This is the first stage of the Git project lifecycle and this is the local working directory where your project resides and this shall not be tracked.
Initialization: For initializing the repository, we can use the command git init. By using this command, you can make the Git notified of the project file that is found in the repository.
Commit: Also, now you can commit all the files by utilizing the git commit -m 'our message' command.
Staging area: Here your source code files, configuration files, and data files are tracked by Git and you can add those files which you need to commit into the staging area by using the git add command. This course can also be called indexing. The index comprises the files that are added in the staging area.
Git Workflow
Here in this DevOps tutorial for beginners, you will be introduced to the various workflow options that are available in Git. When you get familiar with these workflows, you can easily choose the right workflow that is apt for your team project. Based on the team size, you can choose the exact Git Workflow which is appropriate for your team, and it increases the credibility of your project as well as increases your productivity.
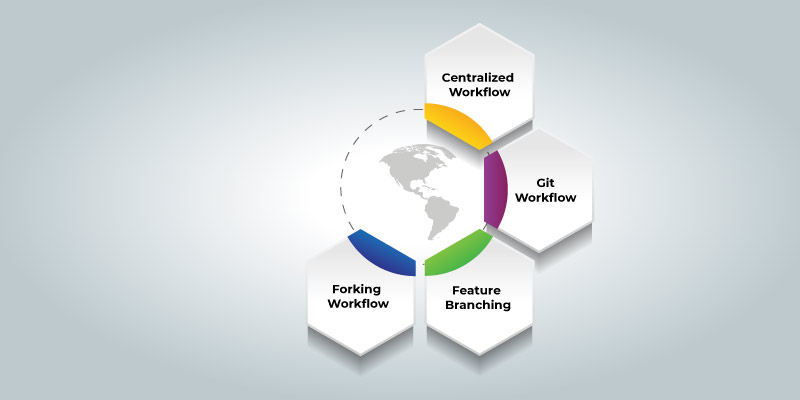
Centralized Workflow: In the Git Centralized workflow, there is only space for the development branch and this is called the master, and all the changes are delegated into this one branch.
Feature of Branching Workflow: With the feature of the Branching workflow, the feature of the development shall occur only in the specific feature of the branch. The image that is given below shall depict the functioning of the branching workflow
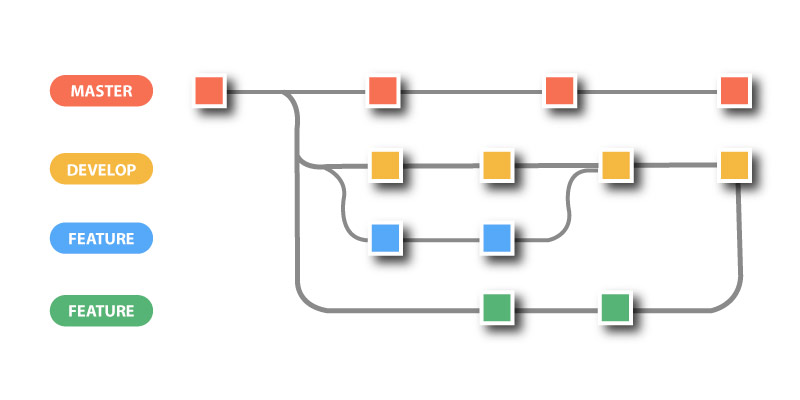
Git Workflow: Rather than a Single Master branch, the Git Workflow shall make use of the two branches. And here the Master branch stacks the authentic release history and the second 'develop' branch functions as the integration branch for their features. The below image explains the Git Workflow:
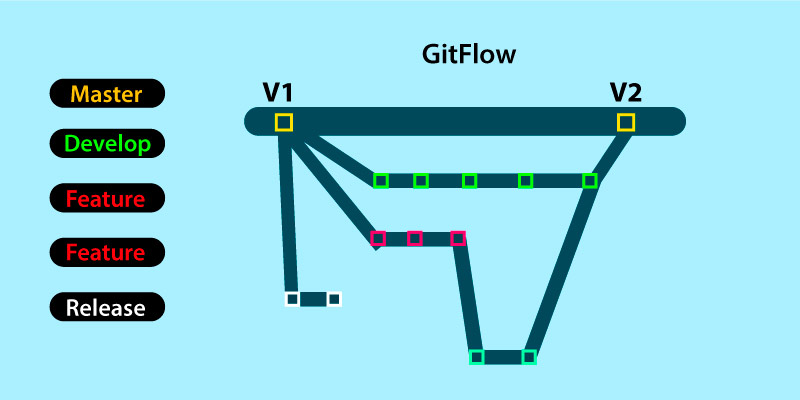
Forking Workflow: In terms of the forking workflow, the contributor has two Git repositories and they are one private local repository and the other is the public server-side repository. The DevOps Training in Bangalore at FITA Academy helps the students to enrich their knowledge of the DevOps concepts and its tools under the mentorship of real-time professionals.
DVCS Terminologies
Local Repository: All the VCS tools offer the private workplace for the working copy. The Developers shall make the changes on the private workplace and after the commit, those changes take part in the repository. Git takes it one step higher by offering them the private copy as the complete repository. The Users shall perform more operations with this repository like adding the file, renaming the file, removing the file, commit changes and moving the file.
Index or Working Directory & Staging Area
It is only in the Working Directory where all the files are verified. Whereas in the other CVCS, the developers usually make the modifications and they commit their changes straightly to a repository. However, Git makes use of different techniques and strategies. In general, Git won’t necessarily track all the modified files. At any point in time if you perform a commit operation, then Git searches only for the files that are found in the staging area.
DevOps Note: In this process, only the files that exist in the staging area are treated for the commit and not every modified file.
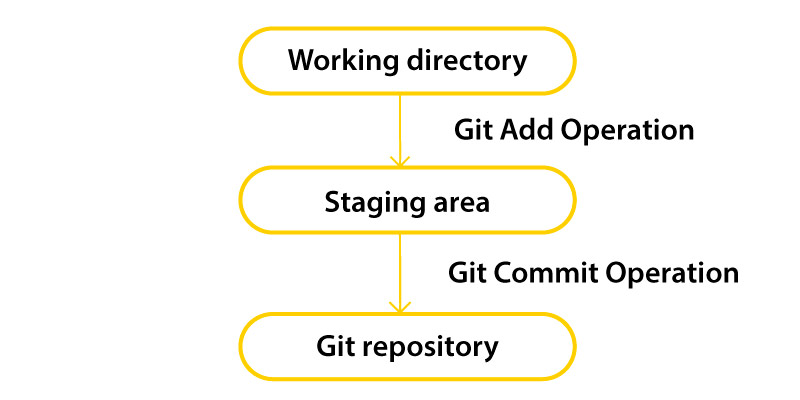
Below we have given the outlook of the fundamental workflow of the Git
Step 1- From a working directory, modify the specific file.
Step 2 - Place the changed files in the staging area now.
Step 3 - Commit operations are used to move files from the staging area to the production area. When the push process is finished, the changes are permanently stacked in the Git repository.
DevOps Notes:
In case, if you have modified two files - "sort.g" & "search.g". Now if you need two different commits for every operation then you can add one of the files on the staging area and you can perform the commit. Once you are done with one specific commit, you can repeat the same process for the next file.

Blobs: The expansion of the term Blob - Binary Large Object. All the versions of the file are characterized using a blob. The blob holds all the file data. Also, it will not consist of any metadata of a file. This is the binary file and in Git Database this is called the SHA1 hash of that specific file.
DevOps Notes: In Git, generally the files won't be addressed by the names rather all are content-addressed in the Git.
Trees: The tree is the object that embodies the directory. It has blobs and the other sub-directories. The tree is the binary file that stores all the references to the trees and blob.
Commits: The Commits consist of the current position of a repository. The commit is also called by SHA1 hash. Also, here you can regard the commit object as the node that is linked to the list. All the commit objects consist of a pointer to the corresponding parent commit object. It is possible to peek into the history of a commit by traversing back and looking into the parent pointer from any given commit. When a commit is made up of multiple parent commits, the two branches are merged to create the final commit.
Branches: Branches are commonly utilized to create the other development line. The Git by default consists of a master branch that is similar to the trunk in the subversion. Mostly, a branch is developed with the intent to function on the new feature. If the feature is developed completely, then this is combined back to the specific master branch and you can delete that branch. All the branches are accredited by the HEAD and this helps in pointing to the recent commit that is found in the branch. Irrespective of how many times you make a commit, the HEAD is always updated with the commit that is recently created.
Tags: It helps in assigning useful names with the specific version that is found in the repository. The tags are similar to the branches however the fundamental difference is that the tags are immutable. It indicates that the tag is the branch that nobody prefers to modify. Once if you have created a specific commit, even when you create a new commit, then it would not be updated. Generally, the Developers create these tags mainly for product release.
Clone: The Clone is the operation that shall create the instanceof therepository. The Clone operation does not check for any working copy however, it reflects the complete repository. The Users could perform more operations with the aid of a local repository. And here the Networking gets involved only when repository instances are synchronized.
Pull: The Pull Operation copies the changefrom the remote repository instance to the local one. The Pull Operations are used for the synchronization of two repository instances. It is the same as the update operation in the Subversion.
Push: The Push operation copies the changes from the local repository instance to the remote one. It is mainly used for stacking the changes constantly in the Git repository. It is the same as that of the commit operation in the Subversion.
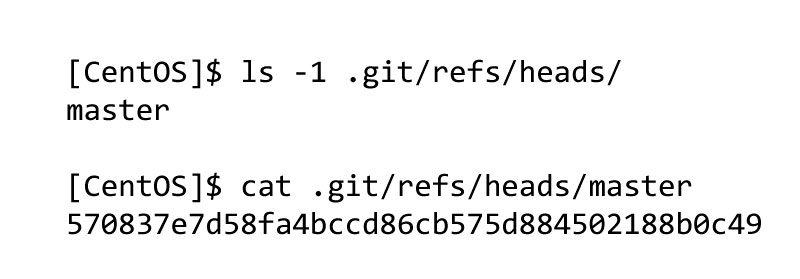
Head: The HEAD is the pointer that points to the recent commit that is found in the branch. When you make a commit, the HEAD is updated on the recent commit. The heads of the branches are stacked in the .git/refs/heads/directory.
Revision: The Revision depicts the different versions of a source code. The Revision in Git is characterized by the commits. These are the commits that are found by the SHA1 secure hashes.
URL
The URL depicts the location of the Git Repository. The Git is the URL that is stacked in the config file.
Jenkins
In this DevOps Tutorial session, we have primarily focused on the Jenkins tools functions and features in-depth. Jenkins is the Software that permits the users to perform continuous integration on the software/application life cycle.

What is Jenkins?
Jenkins is an open-source automation tool that allows for continuous integration and is based on the Java programming language. The Jenkins test and builds software projects which persistently makes it simpler for a developer for integrating the changes in a project and thus makes it easier for the users to gain the fresh build. It also enables you to provide software on a continuous basis by combining it with a variety of deployment and testing platforms.
With the aid of Jenkins organizations, could easily boost the software development process via automation. Jenkins also helps in integrating the development life-cycle processes of different kinds and it includes test, document, package, stage, deploy, build, static analysis, and many more. Jenkins helps in accomplishing the Continuous Integration with the support of the Plugins. The Plugins permit the integration of different DevOps stages. In case if you need to integrate the specific tool, you should install the plugins properly for that specific tool. For instance Amazon EC2, HTML Publisher, and Maven 2 Project.
For instance: In case if any organization is working on developing the project, then Jenkins will help in continuous testing of your project and it helps in project building and it showcases how the errors have taken place in the initial stages of development.
Attributes of Jenkins
The below are some of the interesting details of Jenkins which makes it the best tool for Continuous Integration when compared with other tools.
Adoption: The Jenkins is spread all across the globe and it has over 1,47,000 active installations with a total of 1 million users across the world.
Plugins: The Jenkin is a well-interconnected tool with 1,000+ Plugins that permits you to integrate the predominant development, testing, and deployment of the tools. Also, it is clear from the above that Jenkins is demanded immensely across the globe.
Before diving deep into the DevOps tools tutorial Jenkins, let us have a clear understanding of what is Continuous Integration.
The term Continuous Integration is the development practice in which the developers and others are required to commit the changes on the source code and also in the repository that is shared numerous times periodically in a day. All the Commit is made on the repository and then only it is built. It permits the team to check the problems at an earlier stage. Further, upon relying on the Continuous Integration tool, you have numerous other functions like deploying and building the applications on a test server for helping the concerned team with the required builds and test results.
Continuous Integration with Jenkins
Over here, let us consider a situation where the entire source code of an application is built, developed, and deployed on the server for testing purposes. On the outlook, it may seem to be a perfect method for developing software, however, this process incurs many issues and we have listed them below.
- The Developer team should wait until the complete software is developed to test the results.
- It has a good chance of succeeding in general, and the test will uncover several flaws. The developer’s task of detecting those issues was made harder by the fact that they had to cross-check the entire source code for the application process.
- It slows down the complete software delivery process
- The continuous feedback which is connected to the things such as coding issues, building failures, test status, architectural issues, and other file release and uploads that were found missing and this immensely impacts on the quality of a software.
- The entire process was manual and it increased the peril of constant failures.
From the above-mentioned points, it is evident that the problems not only impacted the latency of the software delivery process it also affected the quality of the software. It leads to increased customer discomfort.
To overcome such issues, the organizations were in dire need of a competent system where the developers could frequently trigger the build or test for all the changes that are made on the source code. Over here Jenkins came as the rescuer for the developers. Jenkins is one of the most mature and high-level CI tools that are found in the market. The DevOps Training in Hyderabad at FITA Academy enables the students of the DevOps training program to obtain an in-depth understanding of the DevOps concepts and its tool in real-time applications with certification.
To have a precise understanding of Continuous Integration with Jenkins the flow diagram that is given below will help you to understand it.
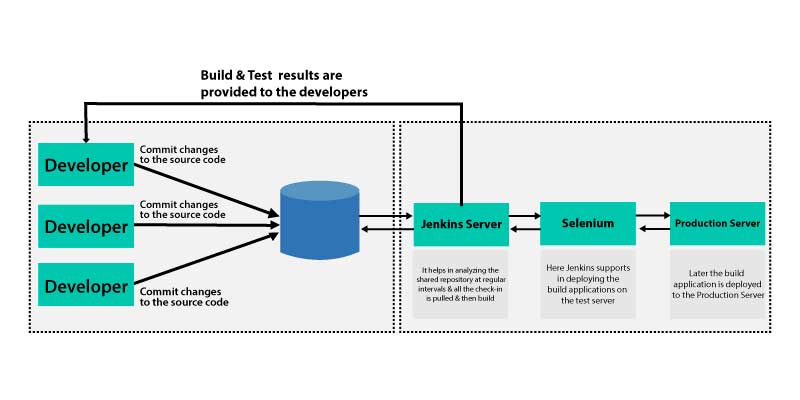
In the above illustration, the Developer should commit the code to the corresponding source code repository. Also, Jenkins would check in the repository during regular intervals for modifications.
- Once the commit takes place, then the Jenkins server shall find the changes that have taken place in the source code repository.
- Then the Jenkins would extract those changes and shall begin to prepare the new build.
- In case if the build fails, then those respective teams would be notified.
- In case if the build is successful, then the Jenkin Server shall deploy the built-in after the test server.
- Once the testing is done, the Jenkin server shall generate the feedback, and then it could notify the respective developers of the build and test results.
- Also, it would continue to check the source code of a repository to bring in the changes that are initiated at the source code level, and then the complete process shall keep repeating itself.
Merits on using the Jenkins tools
- Jenkins is an Open-source tool and also it is completely free to use
- You are not required to spend any additional charges for components or installation set-up.
- Jenkins is a user-friendly software which means you can easily install & configure them
- Jenkins is capable of supporting 1,000 or above plugins and this eventually eases your workload. In case if there is no Plugin then, you can write the script for it and also share them with the respective community
- As Jenkins is built using Java it is highly portable
- Jenkins is a platform-independent tool and it functions efficiently on all operating systems like Windows, Linux, and OS X
- You have huge community support as it is an open-source software
- The Jenkins also renders the support of the Cloud-based architecture with which you can deploy the Jenkins on all the Cloud platforms.
Architecture of Jenkins
Jenkins Single Server: The Jenkins Single Server was not sufficient to meet some of the criteria like:
At times you may need numerous different environments for testing your builds. It is impossible to be achieved with a Single Jenkin Server.
When heavier and larger projects are built on a continuous basis then the Single Jenkins Server can not handle the complete load efficiently.
So, to address the above-mentioned requirements, Jenkins bought the Distributed Architecture into the play.
Jenkins Distributed Architecture
Jenkins manages distributed builds using the Master-Slave Architecture. The Master and Slave communicate using the TCP/IP protocol.
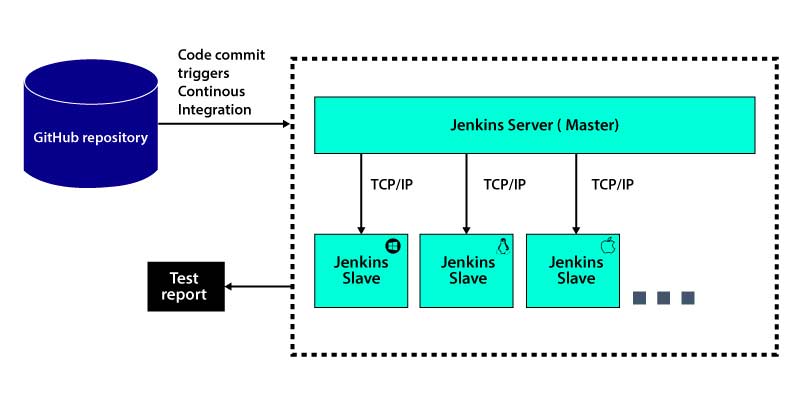
Jenkins Master
Jenkins' Master is the main server. The Master's job is to manage the below activities
- Scheduling the build jobs
- Rapidly send the builds to the corresponding slave for actual execution
- To check the Slaves
- To keep track of and present the build's progress
- The Master instance of the Jenkins could be used for executing the build jobs directly
Jenkins Slave
- The Slave is the Java Executable
- A Java executable that executes on a distant machine is known as a slave. Jenkins Slaves have the following characteristics:
- It pays attention to the Jenkins Master Instance's demands
- Many operating systems are incompatible with the Slaves
- The Job of a Slave is to execute the functions as they are instructed and it involves building the jobs that are dispatched by Master
- Also, you can configure the project for running the specific Slave Machine or just allow Jenkins to choose the next available Slave
The image given below will clearly explain it. The Jenkins consists of the Masters that are capable of handling the three Jenkins Slave
Functioning of Jenkins Master and Slave
Look deep into the example, where we make use of Jenkins for testing various environments such as MAC, Windows, and Ubuntu. The diagram given below would depict the same
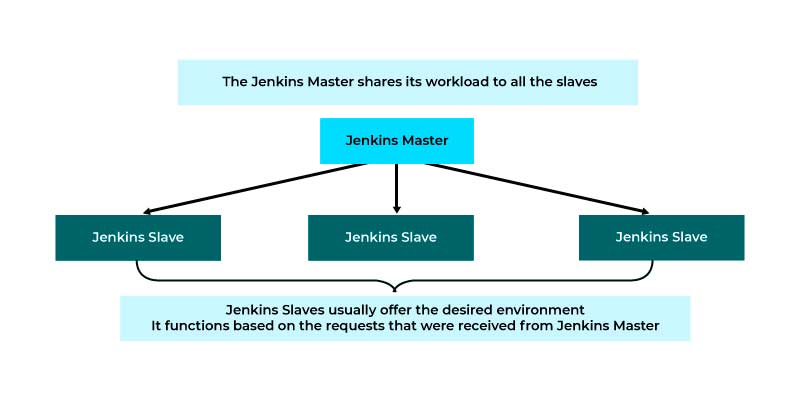
The above diagram depicts the following
- The Jenkins check the Git repository only during the periodic intervals for the changes that are made in the source code
- The builds need a different testing environment and it is not feasible when you are doing it on a single Jenkins Server. To perform the testing in various environments, Jenkins uses different kinds of Slaves as interpreted in the above diagram
- Also, the Jenkins Master request those Slaves to exhibit the testing and generating the test reports
Downsides of Jenkins
Jenkins too has its share of demerits. Some of them are:
Developer Centric: Jenkins focuses more on the feature-driven and developer-centric prospects. The person should have some kind of developer experience to make use of Jenkins.
Setting Change Issues: There are few issues like Jenkins not starting up and that you may face when you have to change its settings in Jenkins. The issues could arise when you are required to install the plugins as well. Luckily, Jenkins has a wider user base so you could easily search for an online solution when you are faced with some issues.
Jenkins Applications
Jenkins aids its users to accelerate and automate the Software development process rapidly. Below are some of the common applications of the Jenkins
Increased Code Coverage: The Code Coverage is generally identified by the total number of lines of the code that a component consists of and how far it is being executed by them. Jenkins generally increases the coverage of the code and it ultimately encourages the transparent development process over its team members.
No Broken Code: Jenkins makes sure that the code is tested and that it is good. Jenkins also ensures that it has gone through continuous integration. Finally, the code is merged only when the entire test turns out to be successful. It also ensures that no broken codes are shipped into the production.
Key Features of Jenkins
The Jenkins offers its users more attractive features and some of them are listed below:
Easy Installation: Jenkins is a Java-based, self-contained, and platform-agnostic application that is ready to run on a variety of platforms, including Mac OS, Windows, and Unix-like OS.
Easy Configuration: It is easy to set up the Jenkins and configure them using the Web interface features for checking errors and also for built-in help functions.
Available Plugins: There are over a hundred available plugins in the Update Center that are used for integrating each tool that is found in the CI and CD toolchain.
Extensible: The Jenkins can be extended by different means such as Plugin Architecture to offer endless possibilities to its users.
Ease of Distribution: The Jenkins could easily share its work over different machines for faster testing, building, and deployments over different platforms.
Free Open Source: The Jenkins is the Open-source resource pool that is backed by large community support
Ansible
Here in this DevOps tools tutorial, we are going to see about the Ansible tool. This DevOps Tutorial for Beginners provides a fair understanding of the Ansible tool and its role in the DevOps process. Before going in-depth first let us know what Ansible is all about?

What is Ansible?
Ansible is the open-source IT automation engine that automates applications such as deployment, provisioning, orchestration, configuration management, and many other IT processes. By using Ansible you can easily install the Software, enhance security & compliance, automate the day-to-day task, patch systems, provisioning infrastructure, and share the automation over your organization.
The Ansible is easier to deploy as it does not need any customer security infrastructure or user agents
The Ansible makes use of the Playbook to explain the automation jobs and the playbook makes use of a simple language called YAML which could be easily read, written, and comprehended by humans.
The Ansible is designed in the format of multi-tier deployment. Ansible does not handle only one system at a time, it is capable of modeling the IT infrastructure by defining all your systems and it is interrelated. On the whole, Ansible is agentless and it means that Ansible operates by connecting your nodes via ssh(by default). However, when you need the other mode of connection namely Kerberos, then Ansible provides you that option.
Advantages of using Ansible
Agentless: The Ansible does not require any agents to be installed on its remote system for management. It means it has significantly fewer performance issues and maintenance overhead. Ansible primarily makes use of the push-based approach to leverage the existing SSH connections for running the task on the remotely handled host. The Chef or the Puppet would work by installing the agent on the host to handle and thus the agent pulls the changes right from the control host by using its channel.
Ansible is built using Python: The Ansible framework is written in Pythonand it implies that installation and running of the Ansible in any of the Linux distributions is easy. Python being a popular programming language, there are higher possibilities that you could easily understand and become familiar with this tool and that you have a large back-up to help you out at any time during the DevOps process.
Deploys the Infrastructure in the Record time: The Ansible could possibly send the tasks to different remotely handled hosts concurrently. It signifies that you can execute all the Ansible tasks within seconds and handle the host without having to wait for it to be completed on the first for reducing the provision time and for deploying the infrastructure robustly than ever before.
Ansible is easier to understand: The key highlight of Ansible is its learning curve. Any beginner can effortlessly comprehend the Ansible tool. Also, the thing you have to note here is that troubleshooting in Ansible is simple and also the chances of committing an error are meager here.
Ansible Workflow
Ansible generally functions by bridging your nodes and pushing them out to the small program termed Ansible modules. Once these modules are executed it shall remove them when it is accomplished. Also, the Library of these modules shall nest on any of the machines and there wouldn't be any daemons, databases, or servers needed.
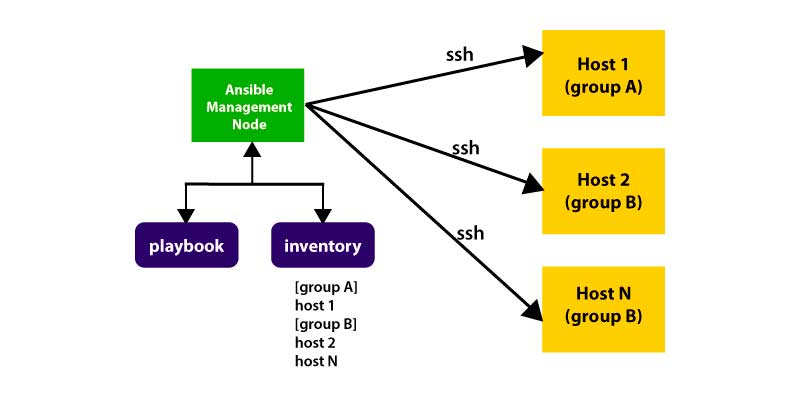
From the above image, it is clear that the Management Nodes are the Controlling Node and it handles the complete execution of a playbook. The inventory file offers the set of hosts where the Ansible has to be run. The Management Node enables the SSH connection and it executes all the small modules of the host machine and thus installs the software.
The inventory file contains a list of hosts on which Ansible modules should be installed. . The Management Nodes utilizes the SSH connection and executes small modules on a host machine for installing the software. The Ansible also removes the modules once when these are installed properly. Also, it connects with the host machine for executing the instruction, and once when it is installed successfully, then it shall remove that specific code in which the actual code has to be copied to the host machine.
Important Terminologies of Ansible
Task: The task is the part that encompasses a single procedure that has to be accomplished
Module: Generally, the Module is the command or a group of similar Ansible commands that are expected to be executed from the client-side.
Ansible Server: This is the Machine where Ansible is stored and only from here all the playbooks and tasks are run.
Role: This is the method of aligning the tasks and other files that have to be called later in the playbook.
Inventory: This file consists of data also about the Ansible Client-Server.
Fact: The details are gathered from the Client System from global variables along with gather-facts operation
Handler: This task is called only when a notifier is identified
Play: This is the Execution of Playbook
Tag: It is the Name set of the task and it could be used later for just issuing certain group tasks or specific tasks
Notifier: This part is attributed to the task that shall call the handler and when the output is modified. The DevOps Training in Pune at FITA Academy provides a wider understanding of DevOps Concepts in cohesion with Agile and Lean mode of IT Operations. Also, the DevOps Training at FITA Academy covers the wide range of tools that are prevalent in the industry.
Ansible Architecture
Ansible Architecture is adaptable and it is a lightweight IT automation engine for automating application deployment, intra-service orchestration, cloud provisioning, configuration management, and other IT tasks. Since it was designed with the intent of multi-tier deployments right from its inception, Ansible helps in modeling your IT infrastructure by defining how all your systems interrelate instead of focusing on a single system at a time. Agents or additional custom security infrastructure are not used by Ansible.
And it is easy to deploy the most important and simple language YAML in the method of the Ansible Playbooks. It permits you to define the automation jobs in the method that accesses plain English.
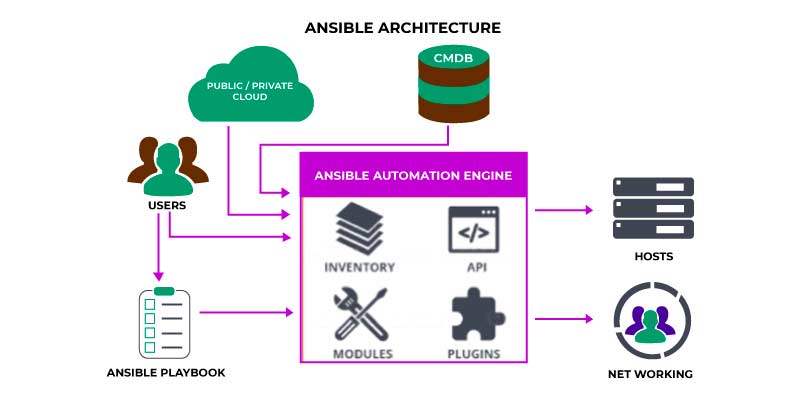
Here in this DevOps tutorial, we will ride you with a quick outline of how Ansible functions and how it laces the rest of the pieces together.
Modules
The Ansible operates by connecting all your Nodes and then pushes out those scripts by calling the Ansible Module. A maximum of the Modules accepts the parameters that are defined in the state of a system. The Ansible later executes all these modules and discards them when it is completed. Also, the library of your modules shall nest on any machine and you need no databases or servers.
In Ansible you can write your modules, however, you must initially consider whether you need that in the first place. Here in Ansible, you will be permitted to work with all your favorite text editor, terminal programs. Also, you can have a VCS to monitor all the changes that take place in your content constantly. You shall write any of the Specialized modules on any of the programming languages (Python, Ruby, Bash, etc) and this could return to the JSON.
Module Utilities
When Multiple modules utilize the same code, then the Ansible shall stack all these functions as the module utilities for reducing the duplication and handling the maintenance. For instance, the code which parses the URLs is lib/ansible/module_utils/url.py. Similarly, you can write your module utilities. DevOps Notes: Mostly, the Module utilities are written in PowerShell and Python.
Plugins
The Plugins amplify Ansible's Core functionality. Plugins are executed on the control node identified within the/usr/bin/ansible process when modules are executed on the target system in a unique process. The Plugins provide the extension, option, and the core feature of Ansible to connect to inventory, transform data, and logging output. The Ansible ships many handy plugins so you can easily write your plugin. For instance, you can write the inventory plugin for connecting any data source and it shall return to the JSON. The Plugins are generally written in Python.
Inventory
Ansible by nature depicts the machine that it shall handle in the file and gathers every machine in a group which you have chosen.
For adding new Machines, you require no additional SSL for signing in to the Server, and it involves no hassles that are used for concluding which specific machine it has not to get linked up. It is due to the DNS and NTP issues. Other pieces of information help you in infrastructure. The Ansible shall also connect them to that. The Ansible will allow you to draw the group, inventory, and variable details from the sources such as OpenStack, Rackspace, EC2, and much more.
For instance, this is how the Plain text of the inventory file looks
If the inventory hosts are listed, then the variables could be assigned into the simple text like (in a subdirectory called ‘group_vars/’ or ‘host_vars/’ files or straightly into an inventory file).
Also, as stated earlier, you can use the dynamic inventory for pulling your inventory from the data sources such as OpenStack, EC2, and Rackspace.
PlayBooks
The Playbooks could easily orchestrate different slices of your infrastructure topology. With the detailed control of how the machines tackle at different times. The Ansible approach of orchestration is remarkably known for its fine-tuned simplicity. Also, it is believed that your automation code would make clear sense to its users down the years and that it consists of only less special syntax to remember them.
Networking
The Ansible is used for automating different networks and this uses the simple, powerful, secure agentless automation framework for IT development and operations. It makes use of the type data model that is separated from the Ansible Automation engine and it spans various hardware easily
Hosts
The architecture of Ansible hosts is the Node systems that are automated using Ansible and machines like Linux, Windows, and RedHat.
APIs
The Ansible APIs function as the bridge of Public and Private cloud services.
CMDB
The CMDB is the kind of repository that acts as the data warehouse for IT installations
Cloud
The Cloud is the Network of Remote servers in which you are permitted to store, process, and handle the data. Usually, these servers are hosted on the internet and it stores the data remotely instead of the local server. It is just used for launching the instances and resources on the cloud and also to connect with the server. So, you are required to have profound knowledge of operating all your tasks remotely.
Ansible in DevOps
As you know in DevOps, the Development and Operation team functions are integrated. The integration is a major factor for modern test-driven and application design. Also, Ansible helps in integrating it by providing a stable environment for both the Operations and Development and it results in continuous orchestration.
Now, let us see how Ansible handles the complete DevOps infrastructure. As soon as a Developer thinks of infrastructure as a component of their application which is nothing but the (IaC) - Infrastructure as Code, performance and stability would turn out to be normative. The IaC is the method of provisioning and handling the compute infrastructure (Virtual Server, Bare-Metal Servers, and Processes) and its configuration via machine-processable definition files, instead of using interactive configuration tools or physical hardware configuration. It is here, where Ansible occupies a prominent position in the DevOps process and thus outperforms its peers.
In the DevOps process, Sysadmins primarily function in sync with the developers and so the development velocity is also enhanced significantly. Further, more time is spent on activities namely experimenting, performance tuning, and thus getting the work done. Also, Ansible takes less time when compared to its competitors. Now go through the image that is given below you will learn how the tasks of sysadmins and others are used for simplifying the Ansible.
Hence, these are the major reasons behind the growing popularity of Ansible in the DevOps process.
Docker
Containerization is a technology which is there in the industry for a longer period. However, with the advent of Docker, this technology has seen paramount growth in the industry. Now let us see Why Containerization is being used widely.
The Containers support the organizations with a logical packaging mechanism and in this, the applications could be briefed from the environment on which they are installed. This decoupling permits the container-based applications seamlessly to be deployed irrespective of their environment. It can be either Public Cloud or the Private Data Center. It can also be an individual's laptop. It gives the developers all the power to create predictable environments and it could be easily detached from the rest of the applications and it can run anywhere. In the aspect of Operations standpoint, besides portability, the container also provides granular control over the resources for giving you the infrastructure to enhance your efficiency and it shall result in the better optimization of your resources that has to be computed. Owing to these enormous benefits, the adoption of containers is widespread in the industry. And over here, Docker is one of the popular tools that is being widely adopted.
Here in this DevOps Tutorial session, we are going to see about Docker, the popular Containerization tool in the industry.

The popularity of Docker has grown tremendously over the past few years and it has certainly created a revolution in the traditional model of software development. The Docker's Container permits the users to scale up immensely and thus it is one of the user-friendly tools. Here in this DevOps for beginners, we are here to make you understand Docker containers, needs, benefits, and environment in-depth.
What is Docker?
Docker is the advanced OS virtualization software platform that enables its users to easily create, run, and deploy applications in the Docker container. The Docker Container is a comparatively lightweight package that allows the developers to pack up the applications and deploy them one by one with the aid of the inbuilt libraries and dependencies. Docker supports immensely in the acceleration and simplification of the workflow. It permits the developers to select the project-specific deployment environment for all projects with various sets of application stacks and tools.
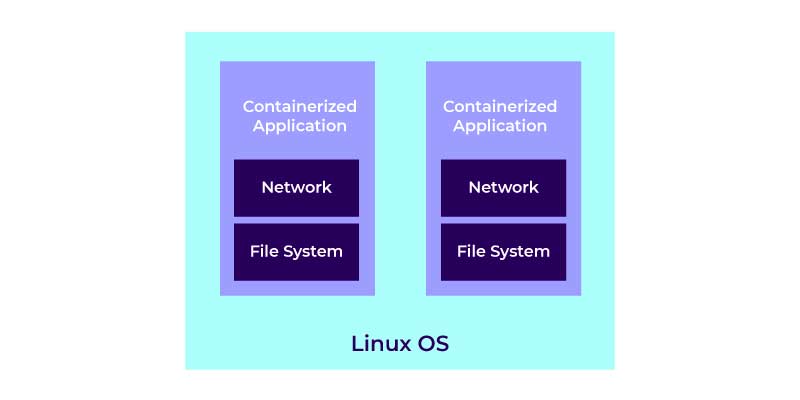
Docker is simple to use and it is highly time-saving. Docker could be easily integrated with the existing environment. Hence, it offers the best portability and flexibility to run the application on different locations be it an on-premise or public, or private cloud service. Docker offers the best solution for the creation and deployment of an application. This Docker tutorial guides you in getting a comprehensive understanding of Docker and its important components.
Application of Docker
Docker is the best tool that is curated specifically for system administrators and developers. Docker is used in multiple stages of the DevOps life cycle for the robust deployment of applications. It permits the developers to build the application and its packages with necessary dependencies in the Docker run container and it allows it to run in any environment.
Docker permits you to develop an application and also its supporting components effectively using the containers. Generally, these containers are lightweight and are capable of installing themselves in the host machine's kernel. Further, it permits running one or more containers in a single container. It offers a free and detached environment that is safe to run different containers at a time on a specific host. Below we have enlisted the places where the Docker tool comes in handy for its users.
Standardized Environment: Docker permits the developers to function in a standardized environment and it helps in aligning the development lifecycle and it reduces the disparity among different environments. Docker is a remarkable tool that is used for Continuous Integration and Delivery workflows which enables the development environment to look more repeatable. Hence, it ensures that all the members of the team are in the same environment and that they are aware of the team members who function in the same environment. Also, this tool notifies its members easily of the development and changes that take place in each stage.
Disaster Recovery: In an unanticipated situation, you could freeze the software development cycle and this could affect the progress of the business severely. However, with Docker, it could be easily reduced. Docker permits the functionality to easily duplicate the Docker image or file to new hardware and it helps in restoring them in case of future references. If there are rollbacks for any specific version or feature, Docker is highly useful to regress the recent version of the Docker images fastly.
It permits deploying the Software without having to think of accidental events. It supports as a great backup for the configuration and hardware failure in case of any workflow disruptions. Also, it helps in resuming the work quickly.
Consistent and Robust Delivery of Applications: Docker permits the testing, developing, and deployment of the applications at a faster pace. The SDLC is generally a long one since it includes testing, identifying bugs, making required changes, and deploying them to see through the final results. Docker permits the developers to identify the bugs at the initial stage of the development process as they could be rectified immediately in the development stage before deploying them to the testing and validation stage. Hence, update of is faster Docker and easier to deploy them by just pushing into the production environment.
Code Management: Docker offers the feature of a highly portable environment in which you could easily run different Docker containers in one specific environment. Docker is capable of balancing between the testing and production environments with the aid of code management. It offers a steady environment for both code development and deployment. It also helps in streamlining the DevOps by standardized configuration interface and thus makes it available to all the members of the team. The Docker containers have enabled the development process to be more scalable and user-friendly. Hence, it safeguards that the interface is standardized for every team member. DevOps Training in Gurgaon at FITA Academy is an intrinsic course devised with the intent to make the students familiar with the best DevOps process and the tools that are prevalent in the industry.
Docker Container vs Virtual Machines
Docker containers are identical to virtual machines by nature. Anyhow, the virtual machine has an extra OS in its complete stack. The Virtual Machine consists of a VM OS and the VM runs on another computer that has its OS.
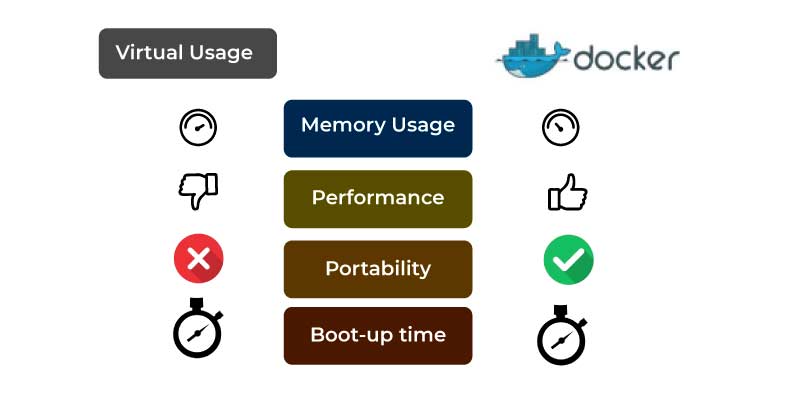
Whereas Docker does not have any internal OS. The container usually runs directly into the host Linux OS. Hence, the Docker container is comparatively small in size, and it won't encompass the complete VM OS. Also, Dockers could perform much better as there is no requirement for virtualization and it is not necessary.
Docker Architecture
Docker makes use of the Client-server Architecture. A Docker client communicates with the Docker daemon, and it performs the running, distributing, and heavy lifting of a building of your Docker containers. A Docker Client and Daemon could run on the same system or you can also connect the Docker client to the remote Docker daemon. Usually, the Docker client and the daemon interact using the REST API with the support of UNIX Sockets or the Network interface. The other Docker Client is the Docker Compose that allows you to function with applications that contain more sets of containers.
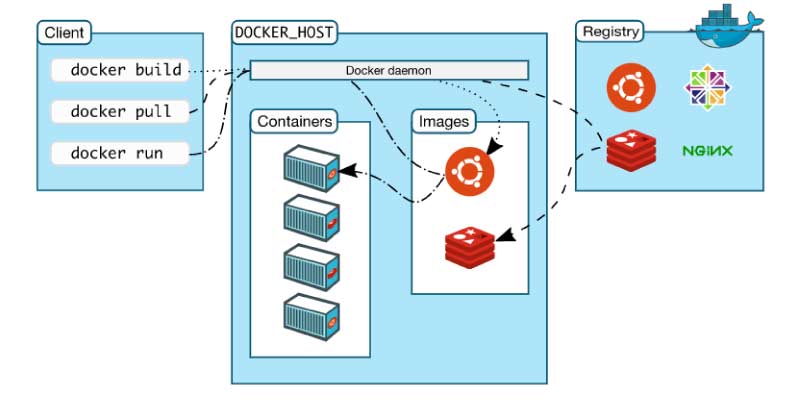
The Docker Daemon
A Docker Daemon or Dockered listens to the Docker API requests primarily. Also, it handles Docker objects like containers, volumes, and networks. A daemon shall also interact with the other daemons to handle the Docker services.
The Docker Client
A Docker client or docker is the fundamental method of many Docker with which the users communicate with the Docker. When you make use of the Commands like docker run, the Client shall send those commands to the "dockerd" that bears them. A Docker command primarily makes use of the Docker API. Also, a Docker Client could possibly interact with one or more daemons.
Docker Registries
A Docker Registry stacks in the Docker images. A Docker Hub is a public registry that could be used by anyone. By default, a Docker is configured to look into the images of the Docker Hub. Also, you can run a private registry for personal use.
While using the docker run commands or docker pull, the images that are needed are pulled right exactly from the configured registry. Also, when you make use of the docker push command, the images that you have pushed are directly configured in your registry.
Docker Objects
When you use Docker, you are primarily using or creating networks, images, containers, volumes, objects, and plugins. This part is a brief analysis of a few of the objects.
Images
The Image is the read-only template with a set of guidelines to create a Docker container. Generally, the image is developed based on other images and additional customization features. For instance, you shall build the image and it is based on Ubuntu. However, it installs an Apache Web Server and your Application as the configuration details that are required to make your application run smoothly.
You shall create the images or you could use only those that are developed by the published and other registries. For building your image, you could create the Dockerfile with simple syntax to define the steps that are required for creating and running the image. Every instruction that is found in the Dockerfile helps in creating the layers in the image. Also, while changing the Dockerfile and rebuilding the image, the layers that have been modified are rebuilt. This is the section that helps the images to look small, lightweight, and fast when compared to the rest of other virtualization technologies.
Containers
The Containers are the Runnable instance of the image. You could easily start, create, move, or delete the container using the Docker CLI or API. You can also connect the container with more than one network to affix the storage in it or also you can create new images that are based on the present state. Generally, the Containers are relatively dislocated from one or the other containers in the host machines. Also, you will have the authority to control the detached container's network storage and the underlying subsystems that are related to other containers from a host machine.
The Container is generally defined using the image and also by any other configuration option to offer you when it is started or created. However, the Container is detached, and the changes that occur in this state are not stacked in the constant storage.
Important benefits and Components of Docker
Docker has modified the functioning of Software Development. Docker helps in boosting the development at a faster pace also it is scalable to handle the different economies of scale. Docker has an advanced platform and it permits IT organizations for testing, creating, and deploying the applications easily in the Docker containers with the support of inbuilt dependencies. Docker is used in different stages of the DevOps cycle however it offers more advantages only in the deployment stage. Docker is highly advanced than the rest of the Virtual Machines and it offers added functionalities that make it preferable for the developers.
However, the Virtual environment consists of the Hypervisor layer and the Docker consists of the Docker engine layer that utilizes lesser memory and thus boosts the operational efficiencies. Generally, a Docker functions via a Docker engine that encompasses two vital elements and they are client and server. And here, the Server transmits the instructions and information to the respective client. But, there are many components of Docker that make it operate seamlessly. It comprises Docker server and client, Docker registry, Docker image, and Docker container.
Where to use Docker?
Docker Streamlines the development cycle by permitting the developer to function on the Standardized environment using the local containers and it offers you all the services and applications. The Containers are highly useful when you are working with CI - Continuous Integration and CD - Continuous Delivery workflow.
Take into consideration the below instance where
- As a Developer, you must write the code locally and share those with peers who are using the Docker containers
- You can use Docker for pushing the application into the test environment for executing the automated & manual tests.
- When the developers identify the bug they shall affix them to the development environment itself and shall deploy them again on the test environment to test and validate them
- Once, when you have completed the testing you can fulfill all the needs of the end user's just like pushing the updated iteration to a production environment.
Responsive Scaling and Deployment
A Docker's Container-based platform permits the developer to push the highly portable workloads. A Docker container could run on the Developer's local laptop on the Virtual or Physical machines on the Cloud providers, in the data center, or the blend of both environments.
A Docker is lightweight and portable in nature and makes it simple for dynamically handling the workloads. You can easily scale up or scale down the applications and services of the business needs and deploy them in real-time practice.
Using the same hardware to run more tasks
Docker is a fast and lightweight tool. It offers the feasible, cost-effective, and other alternatives of hypervisor-based virtual machines so you could make use of more compute capacity for reaching the business goals. A Docker is the best tool for high-density environments. It's also preferable for small & medium-scale deployments, where you'll have fewer resources to work with.
Advantages of Docker Environment
The Docker container is one of the popular Virtual Machines. This Virtual Machine consists of complete copies of the Operating systems namely - necessary libraries, applications, and libraries. These could hold a total space of 10Gbs. For boot, the Virtual Machines are too slow. Whereas, Docker containers only occupy less space in terms of images and efficiently handles the complete applications, and uses fewer Operating Systems and Virtual Machines.
However, they are completely flexible and tenable. Furthermore, using Docker on a cloud is highly beneficial for enterprises. Also, different applications could run on top of a single OS instance and it is a more effective method to run them. The other benefit of the Docker container is the capacity to keep the apps completely isolated from one other and also its underlying systems. It permits you to easily mandate how the allotted containerized unit uses the system resources namely CPU, Network, and GPU. Further, it seamlessly allows the data and code to hover separately.
Docker Containers permits portability
A Docker container is capable of running on any machine and it supports the container's runtime environment. Also, you are not required to tie up the applications to the hosting OS. And both the Application environment and the underlying operating environment could be maintained minimal and clean.
Docker Container allows Composability
A predominant business application comprises different and separate components that are arranged in the stack namely Database, in-memory cache, and the webserver. The containers permit you to compose back those pieces into the functional unit which could be easily changed. The different container offers all pieces so you can easily update, maintain, modify, and swap them self-reliant from others. fundamentally, it is called the microservice model of application designing.
By dividing the application functionality with different and self-contained services, these models provide the best alternative for slowing down the traditional development process along with the inflexible apps. A Lightweight and portable container makes it easier for developing sustainable and Microservices-based applications.
The management of the majority of companies throughout the world relies heavily on Docker tools. Docker tool runs an application with a high level of abstraction and security. Hence, many companies are extensively adopting the tool to achieve high network availability, service continuity, and service provision with high scalability.
Based on the reports submitted by the Global New wire, it is said that the overall need for the Docker tools in the market shall gradually increase to USD 993 million by the end of 2024. The growth of this tool is going to be exponential in the upcoming days as well. To conclude, Docker is an important tool for any DevOps professional since it has more prevalence in the job market. Also, Docker is one of the highly preferred tools among developers.
The DevOps Training in Mumbai at FITA Academy is an immersive course curated with the intent to make the students proficient with the DevOps tools and their application in the DevOps process under the guidance of Expert Mentorship.
Nagios
This DevOps tutorial session focuses majorly on the Nagios tools and their application in real-life environments. In this Nagios tutorial, we will cover with you its features, benefits, architecture, and its role in continuous integration.

The Nagios is the popular Continuous Monitoring tool that is used in a wide array of systems, services, applications, and business processes under the umbrella term of DevOps Culture. Nagios is the open-source monitoring system that oversees and handles small to large enterprise computer networks. With Nagios, you can easily look through the switches, servers, applications, and services. Nagios is one such tool that notifies its users in case of any technical fault and also it can help it, users, with immediate solutions. Mostly the notifications are sent through SMS, Phone calls, and Emails.
Before getting in deep into the Nagios tool, first, let us have a clear conception of What is Continuous Monitoring and why it is needed?
What is Continuous Monitoring?
When an application turns out to be completely active, the need for continuous monitoring comes into play. Continuous Monitoring is all about looking after the company's infrastructure and retorting to the identified bugs or defects spontaneously. Though the technique of static analysis is highly responsible to detect, report, and respond to the log, there are chances where this analysis shall fail to identify the logs and there is also a question on its accuracy level. However, with the aid of Continuous monitoring, you can retort and perform efficiently with the other operations in the best way.
This process is executed constantly based on the reports that are instantly initiated. It indicated the risks that could be encountered by the enterprise because of the poor infrastructure. Also, you could easily check the different activities of a Data Analytics and Network report then and there as needed.
Why does an Enterprise need Continuous Monitoring?
The Continuous Monitoring Tool helps in solving the systems errors and thus help the organizations not harm their business productivity beforehand. Here in this DevOps tools tutorial, we have listed down the reasons for the need for Continuous Monitoring too.
- It helps in finding the Server or Network Problems
- It seamlessly identifies the root cause of any bug or error
- It helps in troubleshooting and checking the Server performance issues
- It aids in handling the Availability and Security of a Service
- It permits the users to have a clear blueprint for the up-gradation of infrastructure and also protect the systems from any outdated failures
- Also, it retorts to any issue initially and it indicates the sign of a problem in the very first place
- Continuous monitoring could easily resolve the problems when identified
- It also protects the IT infrastructure disruption and has the least effect on an organization's bottom line
- It aids you in handling the complete business processes and infrastructure
In short, Continuous Monitoring is the ability of the organization to identify, respond, report, and the one that eases the attack which shall take place in the infrastructure.
DevOps Note: Continuous Monitoring is not a new notion; it has been around for a long time, according to DevOps. For years, the Security Professionals in the Enterprise perform the Static Analysis from the following - Firewall logs, IDS logs, IPS logs, and System logs. However, it failed to provide an accurate response and analysis. Currently, Continuous Monitoring offers the capacity to consolidate the aggregate of every event that is mentioned above. When you consolidate all these issues and try to interlink them there arises the real crux in the Continuous Monitoring method. See the illustration that is given below which will help you to apprehend the crux of Continuous Monitoring.
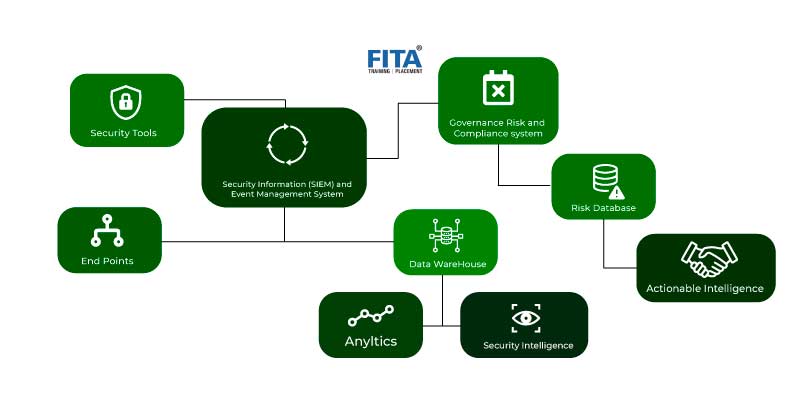
From the above illustration it is distinct that
- There are different Security tools namely Endpoint protection, Firewall, and IDS. The ‘Security Information and Event Management system' integrates all of these tools.
- To accomplish Continuous Monitoring you must consider all the parts that communicate with each other.
- Here we have the Security tools along with a series of "End Points" and it includes the routers, switchers, client & servers, and mobile devices.
- Generally, these two clusters could easily communicate through the (SIEM) Security Informations & Event Management System with a common language in an automated mode.
- While it is associated with SIEM you must have two major components initially, the one where the Data warehouse is identified.
- Now, with this Data Warehouse, you could easily connect with Security Intelligence and Analytics.
- The SI - Security Intelligence is the information that is relevant in safeguarding an enterprise from both the External and the Insider threat like policies, tools, and processes. It is devised in the method to get and analyze that specific information.
- A SIEM is also integrated with the ‘Governance Risk and Compliance System’ to offer the users dashboarding systems.
- For this, the "Governance Risk and the Compliance System are affixed as the risk database. It offers the "Actionable Intelligence"
- That Actionable Intelligence is nothing but the facts that are implied with further implications with which the actions must be taken.
Over here, Monitoring is the events that function based on identifying the level of risk that an organization could encounter. Alongside, you can relate mutually to the events that take place in the SIEM. You can also perform the Anomaly Detection and Network Behavior in the "Analytics Engine" itself.
The assimilation of the organization's security tools, the correlation, the gathering, and the normalization of data is composed by the Security tools. Also, the analysis of data is based on the enterprise's threat and risk factors and also the nearby real-time response. To perform all this, the best tool that is available in the market is Nagios.
What is Nagios?
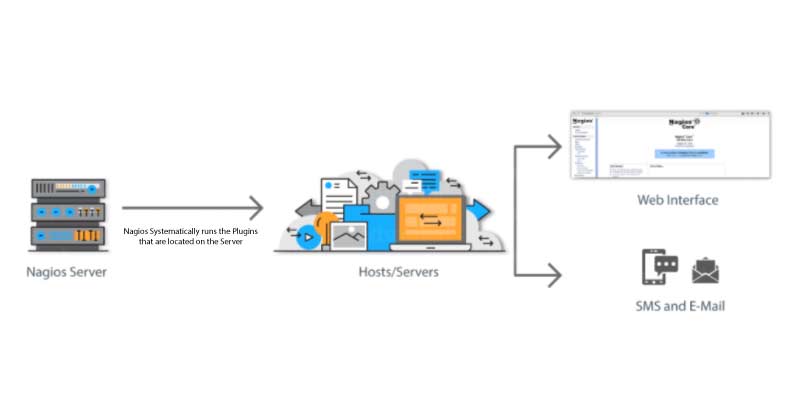
Nagios is the most popular Continuous Monitoring of the applications, services, systems, and business processes that are used in the DevOps culture. Also, it runs the Plugins that are stacked on the Server that is associated with the host or the other server on the Internet or Network. Further, in case of any system failure, the Nagios also alerts the issues that have to be addressed by the technical team for performing the recovery process.
Here in this DevOps tools tutorial, you will be immersed with wider details of the Nagios tool, features, architecture, and the reasons for using the Nagios.
Reasons to use Nagios for Continuous Monitoring
- It is capable of detecting all kinds of server issues and network issues
- It supports you in identifying the origin of a problem and it permits its users to get a rapid solution to their problem.
- It also supports the feature of Active monitoring throughout the complete Business process and Infrastructure management.
- Nagios permits you to troubleshoot and check the entire server performance issues.
- It also supports you in planning the infrastructure upgrades right before any of the system failures
- Also, you could easily handle the availability and security of a service
- It helps you in fixing the issues and the panic situations
Key Features of the Nagios tools
The Nagios has some of the richest features that make it the best tool for Continuous Monitoring. Below we have jotted down the key features of the Nagios tool.
- This tool provides the best attractive Web interface for its users
- The Nagios is immensely scalable and secure
- With Nagios, the users could easily handle it
- The Nagios software provides its users with the perfect option of stacking the data as it consists of a log management system.
- The Plugins of the data graphing are found right inside this application itself
- It characterizes the event handlers that operate during the services
- It also completely supports the backend of a database
- It consists of the option Web Interface to view the Log files and Notifications
- It enables you to implement unnecessary monitoring hosts
- It supports the users to mention the different hierarchy that is identified in the Network hosts by using the parent hosts
- The users shall also easily set up those applications on the "distribute" system and allow you to check the system in different locations of monitoring
- It supports in checking the different services of a network namely FTP, SSH, HTTP, and SMTP
- It permits you to check the different resources of the server likely processor, memory, system logs, and disk drives
- It offers remote monitoring via the SSL and SSH encrypted tunnels
- Also, the Users could easily check or find the complete infrastructure of the Business and IT processes with just a single pass
- It also offers remote monitoring via SSH and SSL encrypted tunnels
Architecture of Nagios
The client-server architecture is Nagios. It usually functions on the Network and the Nagios server shall run on the host and plugins that run on every remote host that should be checked.
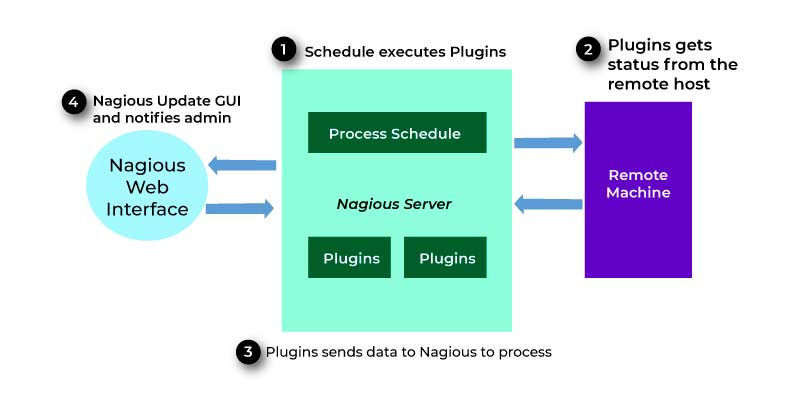
- The Scheduler is an important part of the component's server. Also, it sends the signals for executing the plugins to the remote host.
- The Plugins helps in sending the data to that specific process scheduler
- A Plugin helps in getting the status from the respective remote host
- It helps in processing the scheduler updates and the GUI and Notifications are sent to the respective admins.
Plugins
The Nagios plugins offer low-level intelligence on how to check anything and it checks everything that is related to the Nagios Core.
The Plugins help in functioning and also acts as the standalone application, however, it is curated for executing the Nagios Core. It helps in combining the Apache which is controlled by the CGI to showcase the result. However, the Database is connected with the Nagios for storing the log file.
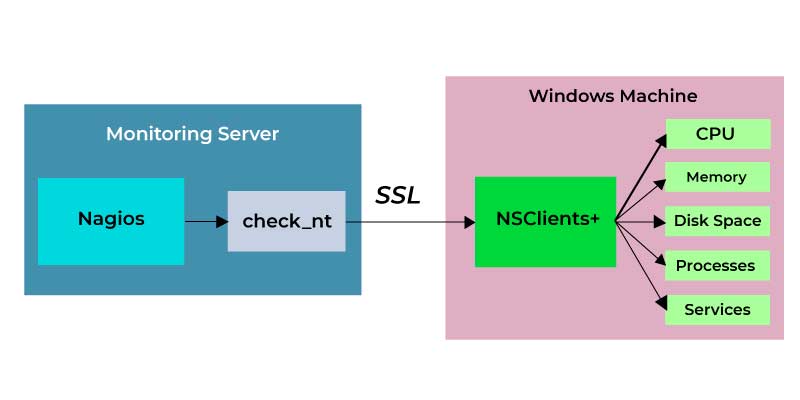
Now, you can take into consideration the examples that are given below
- You can use the Check_nt and it is the Plugin that is used for checking the Windows machine that is commonly found in the monitoring server
- The NSClinet++ shall also be installed in all the Windows machines to check what you wish to check
- There are also SSL connections between the Server and the Host which shall persistently exchange information with one other.
- In the meanwhile, the NRPE - Nagios Remote Plugin Executor and the NSCA plugins are used for checking the Mac OS X and Linux correspondingly.
GUI
The GUI is the interface of the Nagios that is used for showcasing the display on the Web pages that are developed by the CGI. It can either be buttons of the sound, graph, green, or red.

A hard alarm is triggered when a soft alarm is triggered multiple times, and the Nagios server forwards a notification to the administrator.
What do you mean by NRPE?
NRPE - Nagios Remote Plugin Executor is the kind of plugin that permits the users to execute the Nagios plugins on the remote Unix/Linux machine. The main intent of doing this is to permit the Nagios to check "local resources” and utilize the remote machines. The Public resources are not generally exhibited to the external machines for security issues. However, the NRPE should be installed mainly on remote machines. The Nagios Server monitor along with the NRPE on port 5666.
Further, it is possible to execute the Nagios plugin on the remote Unix/Linux machines via SSH. By using the check_by_ssh plugin it permits us to do them easily. Compared to the NRPE protocol, the SSH protocol is more secure. The NRPE is divided into two sections:
- On the local monitoring machine, there is a check nrpe plugin
- The NRPE daemon is normally installed on a remote computer
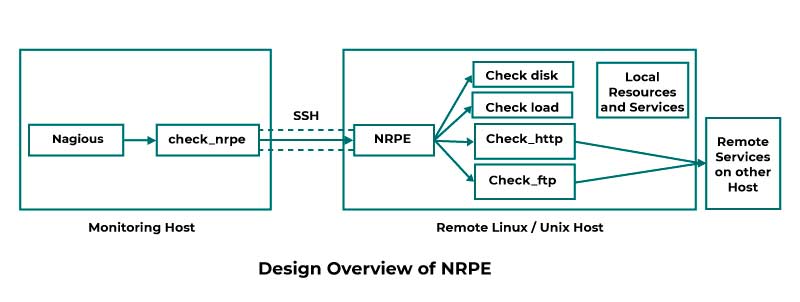
As an example,
Direct Check - It consists of the things such as Memory usage, CPU load, Disk usage, Swap usage, Process states, and Current users.
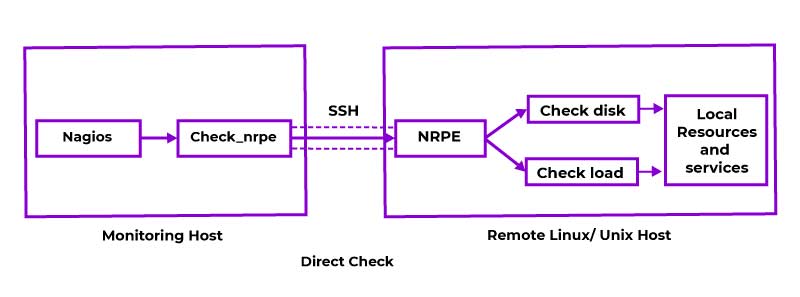
Indirect Check - The NRPE also permits performing the indirect check like "public" services and the resources of a remote server which shall not be reached straightly from a monitoring host. The NRPE daemon fundamentally acts as the proxy in this type of case.
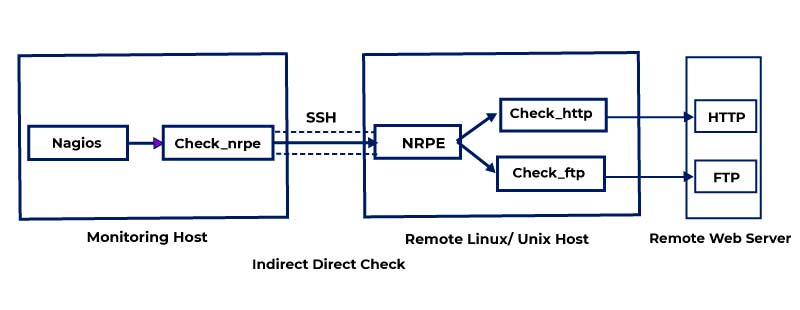
What is NCSA?
The term NCSA stands for Nagios Service Check Acceptor. It's the protocol that's used to reverse the NRPE protocol in Nagios. We can easily submit the passive check results for the Nagios server rather than having them do the active polling. It offers the benefits of remote Nagios applications and servers for sending the passive service check and host to the Nagios server to process. The NCSA plugins encompass two parts
Server Application: It helps in running your Nagios Server and also it listens to the client data transfers.
Client Application: It helps in operating a smooth remote system and they are used by the External applications for sending the data to the specific Nagios Server.
To ensure that the flow between the Server and the Clients is secure, the data will be encrypted.
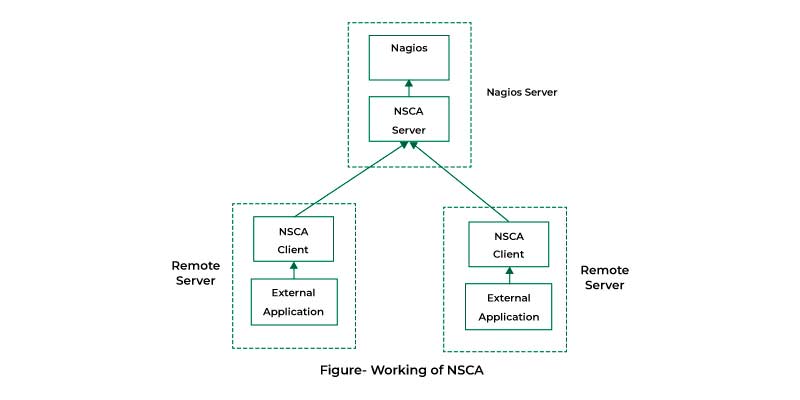
For instance,
The two prime problems that are solved using the Nagios include Alerting and Trending.
An Alert is performed to caution the users who are in charge of the important events namely Service falling to function. Whereas the trending is done to keep the users informed about the changes of anything over the time disk for replication lag and memory usage.
For correct monitoring, the Nagios checks should be chosen wisely and you should tune in which means only notifying really important things. Over here you may doubt how to find which is important? Generally, Nagios offers some services. When the event makes it impossible to offer the service on a pre-defined SLA, then you can consider those events as the important ones. Here is the list of things that has to be noted for monitoring
- When the Host fails to respond
- When the Services fails to work
- When the SLA is broken
- When the one that runs out of important resources: Disk space and Memory
However, it will not caution about the minor issues such as the threshold that exceeded the alert to inform you: that in case of any failure in taking actions, then your applications shall fail to offer the service or the SLA shall be broken. The High Load is the total average and this is the best illustration of a bad alert. However, when the load average is high, but the SLA is not broken then SLA cares only about the Load average.
Application of Nagios
The Nagios is applied to a broader range of applications. And some of them are:
- Check the host resources namely System logs and Disk spaces
- Checking the log files persistently to find the infra-issue
- Checking the Networking Resources like - FTP, SMTP, SSH, and HTTP
- Checking the Windows/Unix/Linux and Web applications and their different states.
- Run the services that check them parallelly
- The Nagios Remote Plugins Executor (NRPE) help in checking the services casually
- An SSL or SSH tunnel shall also be used for remote monitoring
- It supports in sending the Notifications/Alerts
- It aids in sending SMS, Email, and Pager of any issue of the infrastructure
- It helps in suggesting the upgrade of any IT infrastructure
DevOps Training in Delhi at FITA Academy provides holistic training of the DevOps Environment & its functions under the guidance of Expert Mentorship with certification. The DevOps Trainers also cover you with the wide range of DevOps tools and practices that are prevalent in the industry.
Hence these are the reasons that make Nagios the popular tool for the Continuous Monitoring process. It helps the users seamlessly identify, respond to, and alter all the attacks that occur in the core infrastructure. Further, the Nagios is the most securable, scalable, and manageable tool.
Puppet
The Puppet is one of the popular Configuration Management tools that was curated by the Puppet Labs for automating the infrastructure management & configuration. Puppet is the most powerful tool for implementing the Infrastructure as Code concept. The Puppet was written in the Ruby DSL language and it aids in modifying the entire infrastructure in the code format that could be seamlessly configured and handled.

Here in this DevOps Tutorial session, we have presented the complete in and out of the Puppet tool feature, function, architecture, and its applications with illustrations and case studies.
Before getting deep into the Puppet tutorial, let us have a holistic understanding of Configuration Management.
What is Configuration Management?
Configuration Management is the method of handling the computer systems and software (networks, storage, and servers) in the desired, known, and consistent state. It permits you to access the exact historical record of the system state for any audit purpose or project management. Generally, in an organizational setup, the System Administrators perform the tasks mundanely namely installations and configuring those servers. And usually, these professionals should automate these tasks by writing the scripts.
Generally, Configuration Management consists of the following and they are:
- Configuration Identification
- Configuration Management
- Configuration Status Accounting
- Configuration Audits
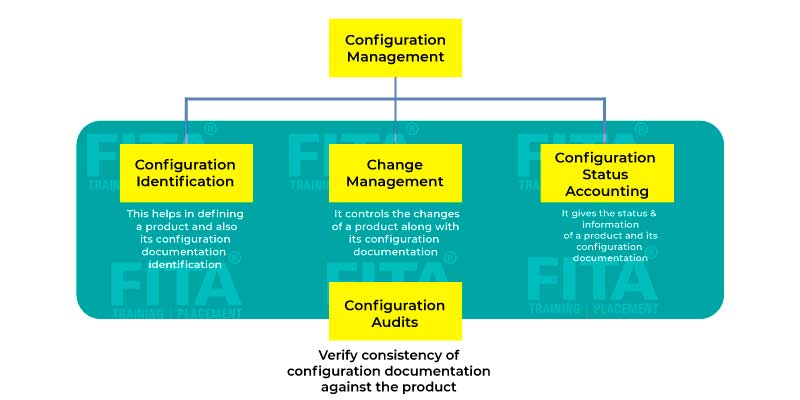
The above illustration clearly explains the components of Configuration Management
Configuration Identification: This process consists of the following
- Classifying the Hardware and Software configuration items with a unique set of identifiers
- It helps in finding the documentation that explains the configuration item
- It helps in organizing the related configuration items on the baselines
- It supports classifying the revisions to configuration baselines and items
Change Management: It is the correct approach of dealing with the changes right from the view of an organization to the view of an individual.
Configuration Status Accounting: It consists of the method of reporting and recording the configuration items on the description like - firmware, software, and hardware. And these are all the departures that are developed on the baseline at the time of production and design. In the event of any suspected problems, the verification of the baseline configuration and the authorized modifications could be identified immediately.
Configuration Audits: The Configuration audits offer the mechanism of finding the right degree to which the present state of a system is persistent with the recent documentation and baselines. Fundamentally, this is the formal method to review for checking the product that is offered while functioning on the promoted, advertised, or any mode through which the customers are promised.
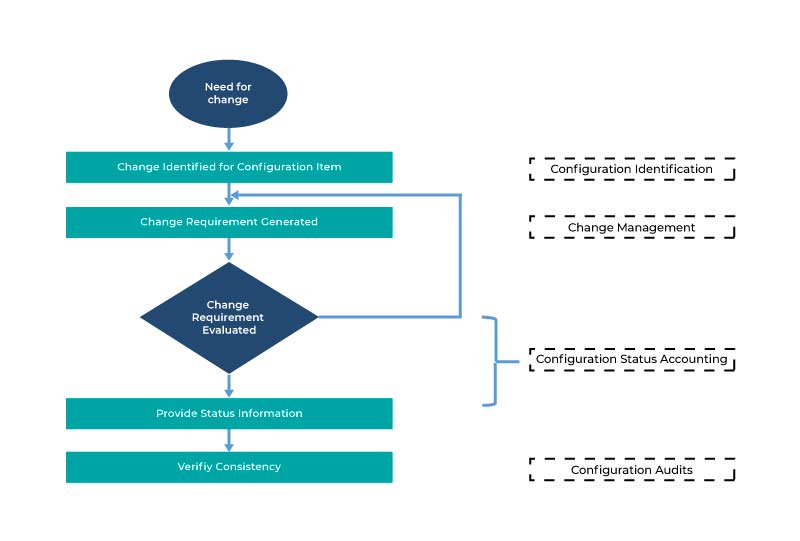
Also, it utilizes the details that are offered as the outcome and also about the quality audits and testing which are offered along with the testing and quality audits. The accounting information is offered as the assurance of what has been built.
However, this is such a perilous job when you work with massive infrastructure. To overcome these kinds of issues in Configuration Management, they introduced the Puppet tool.
What is a Puppet?
Puppet is the most popular DevOps Configuration Management tool. It was developed by the Puppet Lab and it can be easily accessible for both the enterprise version and it is open source.
Also, it is used as the Centralized and Automated procedure for Configuration Management.
The Puppet tool was developed using the Ruby DSL - Domain Specific Language that permits the users to modify the entire infrastructure that is in code format and it could be easily handled and configured.
Puppet tools help in configuring, deploying, and handling the servers. It is specifically used for the automation of the hybrid model of infrastructure management and delivery.
With the support of automation, Puppet allows the system administrators to function faster and easier.
Puppet can be primarily used as the deployment tool since it is capable of deploying the Software of the system immediately. Puppet also helps in implementing the Infrastructure as a code and it means you can easily test the environment for achieving the goal of accurate deployment.
Puppet also supports us with numerous platforms like Microsoft Windows, Red Hat/CentOS/Fedora, Debian/Ubuntu, and macOS X.
Puppet also uses the client-server paradigm, where only one system in any of the clusters functions as the server, and it's called the server. It is called the Puppet Master and the other functions are the client nodes that are called the slave.
Key features of Puppet tool
Platform Support: Puppet is generally suitable with all kinds of platforms which are supported by Ruby namely Microsoft Windows, macOS X, and Linux.
Scalable: Puppet was initially developed in 2005. Hence, many organizations use this tool and they have widely deployed this tool owing to its scalable features.
Documentation: The Puppet offers a wider amount of well-developed and intended pages with in-depth documentation. Puppet has the best documentation.
Idempotency: Just like other configuration management tools, with Puppet, you can easily run the same set of configurations numerous times on the same machine. It means once when you are done with configuration on any specific machine, puppet helps you in checking those configurations in some specific intervals.
Open Source: A puppet is an open-source tool and due to this it could be easily extended and build the custom modules and libraries at ease.
Compliance Reporting: The enterprise version of the Puppet enables the feature of graphical reporting. And with this, you shall easily visualize the infrastructure, communication and respond to the modifications quickly. It supports the users with real-time visibility and enables them to add the effects to change and permits you to see what is happening in the infrastructure.
Economical: In case if you have systems then you should make some sort of code changes then and there. Not only is this time-consuming, but it is also costly. However, with Puppet, you shall easily reduce the total efforts and costs as it is the best management tool.
Faster: The Puppet permits the System Administrators and DevOps professionals to function more effectively and quickly. Owing to this factor a majority of the companies have deployed Puppet to handle their infrastructures like Red Hat, AT&T, Google, Spotify, US Air Force, and AON.
Puppets Architecture and Components
The Puppet generally adopts the technology of Master-Slave Architecture on which the client is called the Puppet Agent or the Slave. Here the Server is called the Puppet Master.
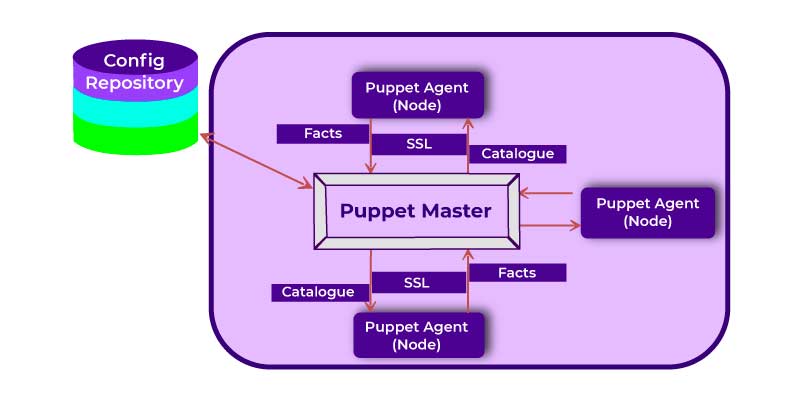
Puppet Master: A Puppet Master generally takes care of the complete configuration-related details. A Puppet Master usually runs on the designated server and manages the complete configuration and deployments.
Puppet Agent: A Puppet Agent usually runs the client. A Puppet agent is the general working machine that is handled and maintained by a Puppet master.
Facts: It is a fact that the global variable consists of the details that are associated with the machines like the Network, Operating Systems, and Interfaces that are used for analyzing the present status of any node.
Config Repository: A Config repository is a place where the complete server-related nodes and configurations are stacked. You can be easily pulled away at any time if necessary.
Catalog: All these configurations are written using Puppet are modified to the compiled format and they are cataloged. Those catalogs are used in the Applied target system.
Modules: The Modules are the set of collections for manifesting the files and positioning them in the way that it offers the features of sharing the files.
Manifests: These are the files where all resources namely - packages, services, and files are needed to be modified, verified, and declared. Generally, the Manifests have a .pp extension.
Modules: The Module is the collection of the manifest files which are categorized in the method it offers the features of sharing of files.
Nodes: All these clients or servers help in handling where the Puppet agent should be installed and they are called the Nodes.
Resources: In Puppet codes, the coding is blocked and characterized by declaring the resources where the resources shall depict the files, users, packages, users, and commands.
Classes: A Puppet is just like any other programming language and it also has classes for grouping the codes better. It also helps them in making it easier to understand and read the code as to how to reuse some specific parts of the code.
Functioning of the Puppet Framework
Puppet has a simple and yet efficient workflow. A Puppet Master consists of all the Configuration details for various nodes and it helps in controlling the usage of manifests.
Here in this DevOps for beginners session let us get to know about the step-by-step method of the Puppet framework
A Node is something that the Puppet Master controls and has the Puppet agents to be installed on them. Those agents are gathered and all the configuration information about these specific nodes is used as facts. Later, these Agents send those facts to the Specific Puppet Master.
Once, when all the details are gathered, the Puppet Master assembles the catalog that is based on how those modes should be configured. A Puppet Master then sends back those catalogs to those agents.
All the agents make use of these catalogs and the information that is given to them for making the required configuration updates. In the respective node and reporting them back to a Puppet Master.
A Puppet Master shall also send those reports with the third-party tool whenever needed.
The DevOps Training in Kochi at FITA Academy hone in the students of the DevOps course on how to use the different DevOps tools proficiently under the guidance of Expert DevOps professionals.
The Puppet Master Server and Puppet Agent Nodes Connection
As you could see, the Puppet Master and the Puppet Agents should interact with each other to allow the Puppet to operate effortlessly. But, how do they do that? Now, let us see that,
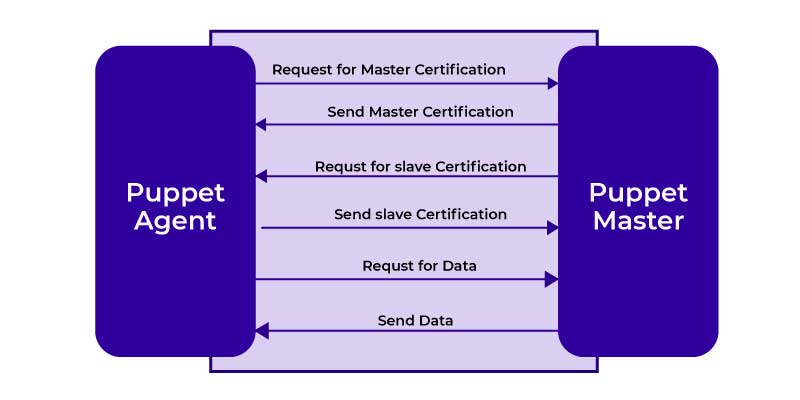
Mostly, a Puppet Master interacts with the Puppet agents through HTTPS - HyperText Transfer Protocol Secure with the aid of client verification. A Puppet Master usually offers the HTTP interface. Whenever a Puppet Agent is pushed to make the HTTPS request to any one of the endpoints that are found in the HTTP interface which are offered by Puppet Master.
Applications of the Puppet
It is a known fact that today most organizations use Puppet. Here in this DevOps tutorial, we will see through the different types and sizes of enterprises that use Puppet.
Consistency and Stability: Years ago the infrastructures were going through a phase of unusual growth and it needed the infrastructure to keep up the pace along with the industry. However, the Script-based Solutions and Manual strategies are not sufficient enough for the requirements that are put forth. Puppet is useful to the enterprises in improving the business growth and also fulfills the infrastructural needs completely. Thus, Puppet is widely acknowledged as the best option when compared to any other scripting solution or manual approach.
Portable Infrastructure: Earlier the infrastructure was required in a way that it could reach the goal of a consistent configuration management approach that is identified both on the Public and Private Data Centers.
Also, Puppet provides consistent configuration management techniques to the respective Data Centers and Public Clouds.
Flexibility: As the property of all the infrastructure differs from one another, it is a tedious job for a team to affix the correct configuration of all systems rapidly. A Puppet offers the feasibility to meet the right set of configurations along with the right machines. And this made the enterprises stay quite flexible using Puppet.
Insights of Infrastructure
To get an outstanding infrastructure, then automatic visualization of all the system's properties is quite needed.
The enterprises shall define all the machine properties with the aid of Puppet and also they shall access those infrastructure insights to handle the servers efficiently.
Collaboration
By now you would have been well aware that Puppet is a model-driven framework. And this feature is simple and easier to transfer the configuration over different enterprises. A Puppet permits the operations and developer staff to function together to assure that the new services render extremely high-quality content.
To conclude Puppet is marching all way long to become the de facto guideline for Configuration Management. Above 75% of the Fortune 500 companies make use of the Puppet tool in the present day. Further, with the aid of Puppet, the System Administrators are capable of accomplishing the entire sets of tasks that once were termed to be tedious. The tasks namely maintaining, operating, enforcing changes, and testing the software irrespective of the places it runs and it does not allow the System Admins to face the difficulty further as the DevOps tool - Puppet acts as the lender of last resort.
Kuberbnetes
The Kubernetes is one of the most extensible, open-source, and portable platforms to handle the containerized services and workloads. This is one of the resilient frameworks that run efficiently on distributed systems. Now before running deep into the waters of Kubernetes in this DevOps tutorial session, let us get to know why we need to know about the Containers.

Why do we need Containers?
Currently, Internet Users will not accept downtime. Hence, the developers should find an alternative method to perform the update and maintenance without any disruption in the services. The Container, that is isolated in different environments. Itconsists of all the things that are required to run an application. It's also simple for developers to deploy and edit apps. Further, Containerization is turning out to be the most preferred form of deploying, packing, and updating Web apps.
Here in this DevOps Tutorial session, let us see about the Kubernetes features, applications, and architecture in-depth.
What is Kubernetes?
Kubernetes is the open-source Container Management tool that is hosted by (CNCF) - Cloud Native Computing Foundation. It is called the upgraded version of the Borg that was created at Google to handle both the batch jobs and long-running processes that were years ago considered as unique systems.
A Kubernetes comes along with the capacity to automate the deployment of scaling of different operations, applications, and functioning of the containers over different clusters. It shall build the Container Centric infrastructure.
What are the tasks performed by the Kubernetes?
Kubernetes is called the Linux kernel that is used along with the distributed systems. It aids you to get the abstract that is found beneath the nodes (server) and it provides a permanent interface for applications that acquire the shared resource pool.
Features of Kubernetes
Below we have listed features of Kubernetes
- Self-Healing Capabilities
- Automated Scheduling
- Load Balancing
- Horizontal Scaling
- Automated rollback and rollouts
- It provides an environment for flexible space for testing, development, and production
- The infrastructure that is offered here is coupled loosely with all components and it acts as the separate unit
- It offers more priority to resource utilization
- It offers the enterprise-ready features
- It provides the infrastructure that is auto-scalable
- It is application-centric management
- Also, you can develop predictable infrastructure
Key Objects of the Kubernetes
Given below are the key objects of the Kubernetes
Service: The Service in the Kubernetes consists of the logical set of pods that function together. With the aid of these services, the users could easily handle the load balancing configurations
Pod: This is the smallest and basic unit of the Kubernetes application. This object helps in indicating the processes that run on the cluster.
Node: The Node is the Single host that is used for running the Physical or Virtual machines. The Node in the Kubernetes Cluster can also be called a Minion.
Namespace: Kubernetes supports many virtual clusters, which are referred to as namespaces. This is the mode of breaking the cluster resources with more than two users.
Replicate set: The ReplicateSet in the Kubernetes is used for searching the specific number of pod replicas that run at a given period. Also, it helps in compensating the replication controller as it is robust and it permits the users to make use of the "set-based" label selector.
Kubernetes Applications
The Kubernetes was initially created with the intent to solve the deployment hassle of any engineer and it helps in working with different technologies that make use of the Containerized solutions like Docker. Here in this DevOps tutorial, we will get you covered with the important applications of the Kubernetes that are used over the different industries.
Deployment of Distributed Workloads
The Kubernetes allows the Developers to deploy their applications in various distributed environments by offering a controllable framework. They also help in connecting the Kubernetes API to handle the application workloads over different containers. It allows them to build a dynamic system that supports automating the Server Management processes.
It also helps in reducing the complete system to backup the Kubernetes feature over different DevOps processes and it is completely in-built. Generally, the Developers make use of this to deploy various kinds of applications.
- Stateless Applications
- Stateful Applications
- Batch Jobs
- Daemons
Managing the Containerized Applications
The Applications which have complex dependencies are generally found challenging during the transfer and execution of updates. With the aid of Kubernetes, this issue is resolved and the applications can be easily chosen from the container. The Kubernetes offers the interface to handle the containerized applications so all the processes right from development to deployment shall be made simpler here. Hence, it consists of the strong use case that is found in the container DevOps and it is difficult to handle other practices.
And it comes with the below-listed features to handle the containerized applications.
- Configuration and Creation of New containers
- Existing containers are being removed
- Setting-up of ports for different containers
- Merging the code from different containers and stacking them into one
- Handling the rollbacks and releases of the containers
Deployment of the Hybrid Cloud Environments
The Kubernetes was created with the intent to support the hybridization of cloud resources. It refers to building a balanced system that makes use of the Virtual Machines that are in coherence with the containerized applications.
A hybrid system eases the business that depends on the legacy of the cloud to accept Kubernetes at ease. This method is termed as building the Heterogeneous Cluster that bangs the perfect balance among the individual and container servers.
Further, Kubernetes permits the use of resources from Public clouds namely AWS & Microsoft Azure. And it is easier to configure the workflow that is used for AWS Elastic Block Storage to perform the constant storage in the solution.
DevOps Automation
The Kubernetes tools help in finding the important application that is found in the domain and it helps in automating the different processes that are related to them. When the applications are deployed over different environments, it is perilous to track all the resources and their usage. However, Kubernetes actively helps in handling the infrastructure for each of them. With Kubernetes, a maximum of DevOps tasks is managed automatically. Below are the important things that have to be followed:
Automatic Resource Scheduling: On configuring the particular resource requirements all the applications of the Kubernetes are immediately scheduled to the specific containers according to the resource usage. It permits dynamic handling of the unused resources and it paves the way to better utilization of resources.
Automatic Rollbacks and Releases: Kubernetes eases the difficult process of releasing the application updates by effortlessly automating them to the release process. In few cases, there may arise a conflict and the health issues are identified in the releases, then the rollback shall also take place immediately.
Automatic Health-Check: The Users could define the automatic health checks that are utilized by the Kubernetes for scanning the applications of any discrepancies immediately. If there is any fault then it is identified or there are chances, where the containers could be crashed inadvertently. The Kubernetes steps in to set right or repair the protocols and thus notifies the system admins as well. The DevOps Training in Ahmedabad at FITA Academy helps the students to learn the DevOps lifecycle right from planning to monitoring stage under the mentorship of real-time DevOps professionals with certification.
Basics of Kubernetes
Here in this DevOps tutorial module, we will get you covered with the basics of the Kubernetes.
Clusters: It is the compilation of hosts(servers) that aids you to accumulate the correct resources. It includes CPU, Disk, and RAM, and other related devices that are used in this pool.
Master: A master is the compilation of different components that build the control panel of the Kubernetes. All these components are used for the cluster decisions. It is inclusive of both the scheduling as well as the responding cluster events.
Node: A single host that can run on either a virtual or physical system. Generally, a Node runs both on the Kube-proxy, Kubelet, and minikube that are termed as the specific part of a cluster.
Namespace: This is the Logical environment or Cluster. It is a broadly used method and is used mainly for dividing the cluster or scoping access.
Kubernetes Cluster Architecture
Here in this DevOps for beginners tutorial, we have given you a clear diagram of a client-server architecture that is followed by the Kubernetes. Also, here we have the Master installed on a specific machine and then the Node to other separate Linux Machines.
Master Machine Components of the Kubernetes
Below we have enlisted the important components of the Kubernetes Master Machine.
- API Server
- etcd
- Controller Manager
- Scheduler
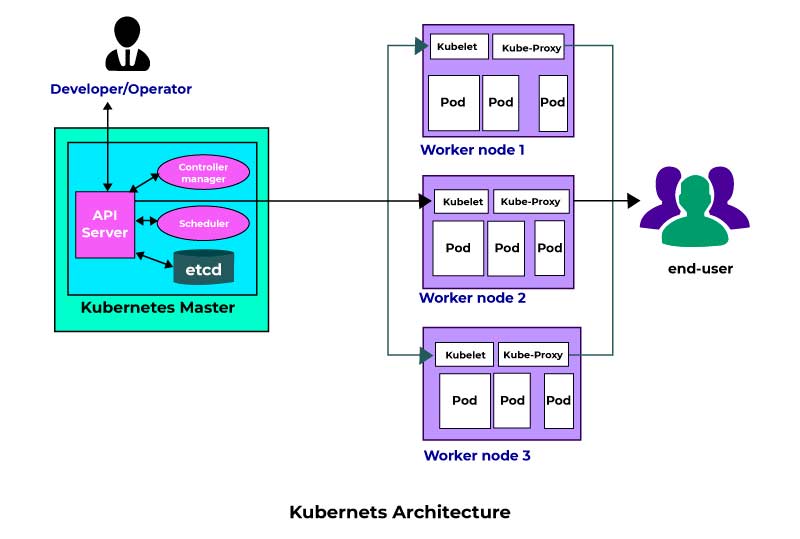
API Server: The Kubernetes is the API server that offers all the operations that have to be performed on the cluster using the API. The API Server helps in implementing the interface that consists of various libraries and tools and the things that could be readily communicated with. A KubeConfig is a package that comes along with the Server-side tools and is used for communication. It helps in exposing the Kubernetes API.
etcd: It helps in stacking the Configuration details and it is mainly used by every node that is found in the cluster. Due to its high availability & key value, you can easily stack it and it could be distributed over different nodes. Further, you can access them only with the aid of the Kubernetes API server and it consists of confidential information. Since this is a distributed key-value store it could be accessible for all.
Controller Manager: This component is important for the majority of the collectors and it helps in regulating the current state of a cluster and executing the task easily. Generally, it could be termed as the daemon that runs on a non-terminating loop. Also, it is bound to gather and send the information to the API servers. Primarily, it works on getting them shared to a state of the cluster and further modify those changes to bring them back to the present state of a server and also the desired state. Endpoint Controller, Replication Controller, Service Account Controller, and Namespace Controller are the most significant controllers. A Controller Manager runs on different types of Controllers to manage the endpoints and handle nodes.
Scheduler: It is one of the important components of the Kubernetes Master. This service in the Master is held responsible to distribute the workload. Also, it is important for tracking the utilization of the workload that is found on the cluster nodes. Further, it helps in placing the workload on the resources that are widely accepted and available for the workload. In layman's terms, this mechanism is entitled to allocate the pods to the respective nodes that are readily available. A Scheduler is more responsible for the workload and also it is important for the allocation and utilization of pods to the newer node.
Node Components of the Kubernetes
Below are the important key components of Node Server that are important for communicating with the Kubernetes Master.
Docker: This is the primary need for all the Nodes that are found in Docker that aids in running the encapsulated application to few containers and they are relatively isolated. However, it operates in lightweight operating environments.
Kubelet Service: It is the small service in all the nodes that are held responsible to relay the details that are provided on the control plane service. It helps in communicating with the etcd right from storing to reading the configuration information and the right values. Also, it interacts with a Master Component for receiving work and commands. A Kubelet process further perceives the obligation of handling the mode of work of a Node server. It aids in handling the Networking port, rules, and forwarding.
Kubernetes Proxy Service: This is the kind of proxy service that runs on all the nodes and supports in enabling the services found right in the external hosts. It also supports sending the request to adjust the containers and it can also perform a primitive load balancing. It ensures that the networking environment is easily accessible and predictable at the same time as it is isolated. It helps in handling the pods on the volume, secrets, nodes, creating new containers, and health checkups.
Addons
It is the list that focuses on just the important add-ons that make use of the Kubernetes resources for initiating the cluster features.
Cluster DNS: The Cluster DNS serves as the DNS record for most of the Kubernetes services. Though the addons are primarily important, the Kubernetes cluster must have the DNS as most of the examples rely on them.
Container Resource Monitoring: This kind of addon is used for recording the generic time-series metrics that are concerned with the central databases containers. Also, it offers the UI to browse the data as well.
Web UI: A Web UI is the general-purpose dashboard for handling the Kubernetes Clusters. It allows the users to handle and troubleshoot those clusters for any applications to run it.
Cluster-Level Logging: This kind of mechanism helps in saving container logs to the specific central log store also with browsing and searching interface.
Other Important Terminologies
Replication Controllers: The Replication controller is the object that helps in defining the pod templates. A Replication Controller also manages the parameters that are used for scaling the identical replicas of the pod horizontally. Also, it is done by increasing or decreasing the total number of running copies.
Replication Sets: The Replication sets are the interaction on which the replication controller designs come along with the flexibility. Also, it explains how a controller identifies the pod that is meant for managing. It helps in replacing the replication controller due to the higher replicate and selection capability.
Deployments: It is the common workload that is being created and managed directly. A Deployment utilizes a replication set for building blocks that adds to the feature of life cycle management.
Stateful Sets: It is the specialized pod that controls the offers under uniqueness and ordering. It is primarily used for having fine-grained control and for the one which you need to have specific requirements like stable networking, persistent data, and deployment order.
Daemon Sets: These are the other methods of a specialized form of Pod controller and it helps in running the copy of the pod on all the nodes in a cluster. This kind of pod controller is the most effective mode to deploy the pods that permits you to efficiently perform the maintenance and thus offers services to the respective nodes by themselves.
Benefits of Kubernetes
- Organizing easily the services with the aid of pods
- It was created by Google, which brings in the years of useful industry experience into the table
- It has the largest community along with container orchestration tools
- It provides different storage options and includes on-premises SANs and Public clouds
- It complies with the principles of the immutable infrastructure
- A Kubernetes shall run on-premises and on the public clouds like AWS, Azure, Google Cloud, and OpenStack.
- It helps you to overcome the vendor lock issues as it could make use of any vendor-specific services or API except where Kubernetes offers the abstraction namely storage and load balancer.
- The Containerization that uses the Kubernetes permits the packaged software to serve the specific goals. It allows the applications that are needed to be updated and released without any downtime.
- A Kubernetes permits you to ensure that those containerized applications run when and where you need them. Also, it helps you to identify the tools and resources that you would like to work with.
To sum up:
Containers aid the enterprises to perform the update and maintenance without any disruption of the service. The Kubernetes is the best example of the Container Management System that is developed by the Google platform. Since it is backed by Google, the Kubernetes popularity is increasing day by day. Further, it has performed well in mission-critical areas like IT, Banking, and Edtech. As organizations today are widely adopting hybrid cloud strategies this is the perfect choice for any organization to go with. The popular companies that use the Kubernetes are Airbnb, Buffer, The New York Times, Pinterest, eBay, Spotify, Pokemon, SAP, Bose, and Reddit.
Gradle
Here in this DevOps Tutorial, we will provide you with complete coverage of the Gradle tool and its application in real-time practice.

The Gradle is the advanced and general-purpose and builds management tool that is developed based on Kotlin and Groovy. It supports in building the completely open-source Automation tool and it is purely based on concepts like Apache Maven & Apache Ant. Gradle was developed with the purpose to serve multi-projects and the ones which are quite big. Further, it has been developed to build automation on different platforms and languages like Android, Java, C/C++, Scala, and Groovy.
What is Gradle?
Gradle is an open-source and builds automation tool that is developed on the concept of the Apache Maven and Apache Ant. It can build any kind of software. Also, it can build any kind of software. It is developed for the multi-project build and it is quite large. Further, it introduces the Java & Groovy-based DSL (Domain Specific Language) rather than XML to declare the project configuration. It uses the DAG (Directed Acyclic Graph) for describing the sequence of a task.
A Gradle is an elastic model that aids in the development cycle right from packing to compiling code for Mobile and Web Applications. It offers support to build, test, and also deploy the software on various platforms. Further, it also offers integration with numerous development tools and servers which include IntelliJ, Jenkins, Android Studio, and Eclipse. Usually, Gradle is applied in large projects namely Hibernate, Spring, and Grails. The important organizations that utilize Gradle are LinkedIn and Netflix. The DevOps Training in Trivandrum at FITA Academy supports and guides the students to become proficient with the DevOps process and the tools that are used in different phases under the training of Expert DevOps professionals.
Before getting deep into the concepts of Gradle first let us learn what is a Build Tool?
The Build tools are the programs that are used for automating the development of executable applications right from the source code. Generally, the building process includes linking, packaging, and compiling the code into an executable and usable form. The Developers commonly implement the build process in a manual method for the smaller projects. However, it shall not be applied for the larger projects where the tasks are highly complicated to keep track of the construction, order, and dependencies that are involved in the building process. Using any of these automation tools enables the build process to be more dependable.
Attributes of Gradle
The Gradle tool has some remarkable features and here in this DevOps tutorial, we have enlisted them in a brief.
Open-source: The Gradle is the Open-source tool that is widely used by developers in the DevOps process and it is licensed under the Apache License (ASL)
High-Performance: A Gradle shall immediately complete the tasks by re-using the output to maximum from the earlier execution. It also only handles jobs that are updated and completed at the same time. Hence, it helps to overcome the clutters easily and provide results at a faster pace.
Supports Ant Tasks
The Gradle offers support to Ant Build projects and we could easily import the Ant build project and also reuse all of the tasks. We will, however, use Ant-based and Gradle tasks. The integration includes a path, characteristics, and much more.
Gradle also supports the Maven repository capability. To fetch and publish a project's dependencies, Maven repositories were developed. As a result, we'll be able to keep using whatever repository infrastructure we find.
Support for Multi-project Builds: The Gradle provides the most robust support for Multi-project builds. The Multi-project build shall consist of the root project and more than one sub-projects. Gradle allows you to simply define layouts.
The projects or dependencies on which a project is based are referred to as dependencies. The graph of project dependencies can be described in this way. Gradle is primarily designed to handle incomplete builds. And it indicates that the Gradle is capable of identifying whether the project needs to be rebuilt or not. In case if any of the projects need to be rebuilt then, the Gradle shall do it before building its project.
Incremental Builds: A Gradle supports us with all the incremental builds and it indicates that it can execute only the required tasks. When you compile the Source code, it shall check whether the sources have been modified right when compared to its previous execution. It can be swiftly performed if the code has been changed; if the code has not been changed, it will skip the execution task and mark itself as updated. In addition, the Gradle contains alternative algorithms that can be used to complete them.
Extensibility: The extensibility of the Gradle is one of its most important features. It is possible to extend the Gradle and it is easier to offer your required build and types models. The best example for this is the Android Build Support where it allows you to add different and new build concepts like build types and flavor.
IDE Support: Gradle now supports a broader range of integrated development environments (IDEs). They allow you to both import and interact with Gradle builds. A Gradle also helps in generating the needed solution files for loading the project into the correct visual studio.
Build Scans: A Build Scan offers holistic details about the build that is used for finding the build issues. It also assists you in analyzing the issues as well as the build's performance. A build scan may be quickly shared with others and is extremely valuable when attempting to resolve a build issue.
Learn Java: We will need a JVM and the Java Development Kit installed on the computer to use Gradle (JDK). Gradle will teach you how to use the vast majority of Java's features. It is mainly a benefit for the users of Java as they could make use of the standard Java APIs in the build logic like custom tasks and plug-ins. As a result, running Gradle on many platforms is much easier. Also, you must note here that Gradle is not only limited to building the JVM projects rather it also offers the Support feature to build the native projects.
Benefits of Gradle
The important benefits of using the Gradle are listed below:
Performance: A Gradle's performance is extremely reliable. Also, it is two times faster when compared to Maven in all kinds of cases and also a hundred percent faster than the large builds that are developed using the build-cache.
User Experience: The Gradle provides a wide selection of IDEs to its customers in order to provide a better user experience. A majority of the people prefer to function on the IDE, and most of the users chose to function on the terminal as Gradle offers the command-line interface to them. Many powerful capabilities, such as command-line completion and Gradle tasks, are available through the Gradle command-line interface.
Highly Customizable: A Gradle is more extensible and customizable. It could be easily customized with different projects under the banner of different technologies. Also, it could be customized in numerous other ways and it could be used in Groovy, Android, and Java projects.
Flexibility: The Gradle is the most versatile tool on the market. Gradle is a plug-in-based build environment. Scala, Kotlin, Java, and Groovy are examples of programming languages that you can use to create your plug-in. In case if you need to add more functionality once the deployment of the project is done, then you should create the plug-in and offer the control to the respective codebase.
Getting to know the history of Gradle
The Maven and Ant had a good share of success in terms of the Java marketplace. The Ant was initially a building tool that was launched in the year 2000. Also, it was built based on procedural programming concepts. Further, it was developed with the capacity to accept the plug-ins and also its dependency management upon the network with the support of Apache-IVY.
The major setbacks of the Ant include:
- The XML that is used as the format for writing the build scripts
- The XML that is relatively unmanageable
- Further, it is hierarchical which is not advisable for procedural programming.
Maven was launched in 2004. And it came along with lots of enhancement when compared to the ANT. Also, it was capable of modifying the complete structure and the XML could be utilized to write the specific build specifications. The Maven depended more on the conventions also it was capable of downloading the dependencies through the network.
The important benefits of the Maven comprise of
- The cycle of the Maven whilst following the similar cycle for different projects persistently.
- The major issues faced by Maven in concern to the dependency management comprises of:
- It is not capable of handling the conflicts over the different versions of the same library.
- A complex and customized build script is much more difficult to write using Maven in comparison to the ANT.
- Hence, to overcome these setbacks, the Gradle came into play in the year 2012 with upgraded features by fusing both the tools.
Features of Gradle
Here in this DevOps tutorial session, we have listed down the key highlight features of the Gradle tool,
Build-by-connection and Declarative Builds
Gradle is found on separate Domain Specific Language (DSL) and is based on the Groovy Language
It offers the Declarative Language elements. These elements also offer build-by-convention support to Java, Scala, Web, Groovy, and OSGI.
Structures your Build
The Gradle permits you to apply the general design principles for your build. It offers you the perfect structure for the build, so you shall design a well-structured and easily handled maintained comprehensible build.
Languages that are used for dependency-based programming
A declarative language primarily depends on the top of the general-purpose task graph that completely supports the build.
Gradle Scales
A Gradle shall easily boost productivity. Also, it could do it away easily right from the simple & single project builds for huge enterprise and multi-project builds.
Deep API
Upon using the API, you could easily check and customize the execution and configuration to its behavior core.
Multi-project builds
Gradle supports its users with the feature of partial builds and multi-projects. In case, when you need to build a subproject, then the Gradle shall take care of the entire building of every subproject and that the sub-project relies on it.
Different methods to handle your Build
The Gradle supports its users with various strategies to handle their dependencies
Ease of Migration: A Gradle can easily handle and adapt itself to any form of structure. Hence, you shall always create your Gradle build in a similar branch, where you shall build the live script.
First Build Integration tool: A Gradle completely supports your ANT tasks. In addition, the Maven and Ivy repository infrastructure helps you retrieve and publish dependencies. It also offers the converter to turn the Maven pom.xml for the Gradle script.
Gradle Wrapper: A Gradle Wrapper permits you to execute the Gradle builds on the machines, where the Gradles are not installed. It is highly useful for the continuous integration of the servers.
Free Open Source Tool: The Gradle is an open-source project and it is licensed under the label of the ASL - Apache Software License.
Groovy
A Gradle's build Script is written in the Groovy Programming language. The complete design of Gradle is similar to using them more as language and not as a framework. Groovy permits you to write the scripts along with a few abstractions. On the whole, the Gradle API is developed using the Groovy language. The DevOps Training in Kolkata at FITA Academy helps the students of the DevOps course to get acquainted with the various DevOps tools and their application in the process with numerous real-time practices.
Career Prospects of DevOps
Currently, the world is looming with technologies day in and day out. And when it comes to technologies it is clear that it tends to fluctuate over time constantly and no such technology is going to remain standstill with the upheaving competition that is prevalent in the marketplace. As the applications and platforms are transitioning themselves at a rapid pace the development technologies that aid this transitioning have also gone through a rollercoaster ride parallelly in the past decade. The concepts like Scrum, Agile, CI/CD, and DevOps have almost set their own path in this digital world. To name a specific technology that has a promising future is DevOps technology. Recently, the spike in the need for skilled DevOps professionals that are witnessed in the industry is more than what you could imagine.
Here in this DevOps tutorial session, we have listed down some of the important factors to be taken into consideration before opting for DevOps as a career option.
Growing demand for DevOps professionals:
Enterprises are rapidly incorporating DevOps practices to meet their client requirements and thus offer them a qualitative service. On adopting the DevOps culture the enterprises were able to prevent & solve the production issues, able to meet the deadlines easily with increased collaboration and communication.
In short, the organizations that implemented the DevOps tools in business processes were enjoying the fruits of more technical benefits:
- The problems were broken into smaller parts and it was resolved easily.
- Continuous Integration and Continuous Software delivery were achieved easily with DevOps.
Business Benefits
- The Faster delivery of the Software features was achieved
- Improved stability was seen in operating environments
- It helped in adding up more time and value to the business
These were the prime factors that pushed businesses of a wide range to shift themselves to use the DevOps-related technologies and thus made them practice and implement the DevOps culture in their business. To add on, the companies are currently deliberately thriving themselves to cut through the competition and stand out in the market with the aid of DevOps technology. This has significantly boosted the demand for skilled DevOps professionals. To adhere to the above-mentioned statement, some of the leading job portals namely Indeed and LinkedIn.com the listing for DevOps professionals stands 75% and 50% respectively. And this listing is anticipated to grow two-fold by the end of 2021.
This is because the DevOps Engineers significantly supported the organizations to optimize their productivity with the aid of automation. To be even more precise, according to a survey report it is mentioned that the organizations that adopt the DevOps Philosophy were able to experience a robust performance and rapid pace of growth i.e, 30 times faster deployment when compared with their rivals in the market. Further to sustain this kind of growth in the businesses the organizations are ready to recruit professionals with higher packages. According to the survey conducted by Dice's 2019 Tech salary report, it is stated that the average remuneration for a Certified DevOps professional is somewhere around $111,683 globally.
Key responsibilities
With the rapid adoption of the DevOps methodologies, the roles & responsibilities for new designations in the industry are growing rapidly. Even though the DevOps experts' skills and responsibilities frequently overlap, companies opt to label these roles independently.
Below are some of the important skills that are mandated in a workspace environment for a DevOps professional
- Application and knowledge of a broad range of technologies & tools in the software development domain
- Getting comfortable with the deployment frequencies & higher testing
- Demonstrable knowledge in Operating the production environment
- The idea of IT systems
- Knowledge of Data Management
- Ability to determine the business outcomes
- Capable of finding and eliminating the silos in the processes by embracing more communication and collaboration
- Improved efficiency and the capacity to utilize the automation tools
- Comprehend the process of Reengineering
- The idea of the production environment
- Good understanding of Project Management skills
- These are the areas where a DevOps professional is expected to have profound knowledge and skills. When they step into an organization as DevOps professionals.
Job titles and Packages
Some of the well-known organizations that recruit certified DevOps professionals are IBM, Accenture, Barclays, Facebook, Bank of America, Cognizant, Infosys, Amazon, Wipro, HP, and TCS. The common job titles that are offered in these companies are DevOps Architect, Release Manager, Security Engineer, Automation Engineer, DevOps Engineer, DevOps Automation Engineer, DevOps Test Engineer, DevOps Architect, Integration Specialists, DevOps Lead, System Admin, and Application Developer. In India, the average package offered for a skilled DevOps professional is Rs. 3,80,000 to Rs. 4,70,000 per annum. These packages differ according to the tools, technical knowledge, and years of expertise you have obtained.
On the whole, in case you are planning to begin your career in the DevOps domain, this is a perfect time to begin with. Anybody who opts for this technology is going to enjoy the fruits of a futuristic career path.
Additional Resources
DevOps Interview Questions and Answers
To conclude:
DevOps is one of the best career options for both the fresher and experienced professionals who are seeking a switchover in their career path. We hope that this DevOps tutorial series was useful to you and that you got a clear picture of the different tools that are utilized in the DevOps process.
DevOps Course at FITA Academy provides you both DevOps Online Course and (Classroom training) DevOps Course in Chennai and at other important cities in India. The DevOps Course at FITA Academy is tailored by DevOps Experts from the industry. Also, the training is offered by skilled and certified professionals from the industry. The Trainers of the DevOps Training program makes you well-equipped with the entire DevOps process and the tools that are used in different phases efficiently. You will have an experiential learning experience where you will be able to implement the things you learned here in real-time practices.
We at FITA Academy, are there to support and guide our learners throughout the training program. The DevOps Training at FITA Academy comes with Placement support which would be of an added advantage for any aspirant who desires to head-start their career as DevOps professionals.
Interview Questions
Interview Questions on Digital Marketing Java Interview Questions For Experienced Selenium Interview Questions and Answers For Experienced Hadoop Interview Questions and Answers For Experienced Python Interview Questions and Answers For AWS Interview Questions and Answers For Experienced DevOps Interview Questions and Answers Oracle Interview Questions PHP Interview Questions For Freshers AngularJs Interview Questions RPA Interview Questions Software Testing Interview Question and Answer Mobile Testing Interview Questions and Answers Salesforce Interview Questions Networking Interview Questions and Answers Pega Interview Questions NodeJS Interview Questions Ethical Hacking Interview Questions Data Science Interview Questions and Answers Javascript Interview Questions Blue Prism Interview Questions SEO Interview Questions Android Interview Questions MS Excel Interview Questions Cloud Computing Interview Questions Cyber Security Interview Questions Interview Question on Tableau Power BI Interview Questions and Answers Artificial Intelligence Interview Questions and Answers Azure Interview Questions and Answers SQL Interview Questions and Answers Full Stack Interview Questions and Answers Dot Net Interview QuestionsFull Stack Interview Questions and Answers UI UX Interview Questions and Answers ReactJs Interview Questions Full Stack Interview Questions and Answers Linux Interview Questions
Contact Us
For Business
Testimonials
Resources
Follow Us
TRENDING COURSES
JAVA Training In Chennai Core Java Training in Chennai Software Testing Training In Chennai Selenium Training In Chennai Python Training in Chennai Data Science Course In Chennai C / C++ Training In Chennai PHP Training In Chennai AngularJS Training in Chennai Dot Net Training In Chennai DevOps Training In Chennai German Classes In Chennai Spring Training in ChennaiStruts Training in Chennai Web Designing Course In Chennai Android Training In Chennai AWS Training in Chennai
iOS Training In Chennai SEO Training In Chennai Oracle Training In Chennai RPA Training In Chennai Cloud Computing Training In Chennai Big Data Hadoop Training In Chennai Digital Marketing Course In Chennai UNIX Training In Chennai Placement Training In Chennai Artificial Intelligence Course in ChennaiJavascript Training in ChennaiHibernate Training in ChennaiHTML5 Training in ChennaiPhotoshop Classes in ChennaiMobile Testing Training in ChennaiQTP Training in ChennaiLoadRunner Training in ChennaiDrupal Training in ChennaiManual Testing Training in ChennaiWordPress Training in ChennaiSAS Training in ChennaiClinical SAS Training in ChennaiBlue Prism Training in ChennaiMachine Learning course in ChennaiMicrosoft Azure Training in ChennaiSelenium with Python Training in ChennaiUiPath Training in ChennaiMicrosoft Dynamics CRM Training in ChennaiUI UX Design course in ChennaiSalesforce Training in ChennaiVMware Training in ChennaiR Training in ChennaiAutomation Anywhere Training in ChennaiTally course in ChennaiReactJS Training in ChennaiCCNA course in ChennaiEthical Hacking course in ChennaiGST Training in ChennaiIELTS Coaching in ChennaiSpoken English Classes in ChennaiSpanish Classes in ChennaiJapanese Classes in ChennaiTOEFL Coaching in ChennaiFrench Classes in ChennaiInformatica Training in ChennaiInformatica MDM Training in ChennaiData Analytics Courses in ChennaiFull Stack Developer Course in ChennaiHadoop Admin Training in ChennaiBlockchain Training in ChennaiIonic Training in ChennaiIoT Training in ChennaiXamarin Training In ChennaiNode JS Training In ChennaiContent Writing Course in ChennaiAdvanced Excel Training In ChennaiCorporate Training in ChennaiEmbedded Training In ChennaiLinux Training In ChennaiOracle DBA Training In ChennaiPEGA Training In ChennaiPrimavera Training In ChennaiTableau Training In ChennaiSpark Training In ChennaiGraphic Design Courses in ChennaiAppium Training In ChennaiSoft Skills Training In ChennaiJMeter Training In ChennaiPower BI Training In ChennaiSocial Media Marketing Courses In ChennaiTalend Training in ChennaiHR Courses in ChennaiGoogle Cloud Training in ChennaiSQL Training In Chennai CCNP Training in Chennai PMP Training in Chennai OET Coaching Centre in Chennai
Are You Located in Any of these Areas
Adambakkam, Adyar, Akkarai, Alandur, Alapakkam, Alwarpet, Alwarthirunagar, Ambattur, Ambattur Industrial Estate, Aminjikarai, Anakaputhur, Anna Nagar, Anna Salai, Arumbakkam, Ashok Nagar, Avadi, Ayanavaram, Besant Nagar, Bharathi Nagar, Camp Road, Cenotaph Road, Central, Chetpet, Chintadripet, Chitlapakkam, Chengalpattu, Choolaimedu, Chromepet, CIT Nagar, ECR, Eechankaranai, Egattur, Egmore, Ekkatuthangal, Gerugambakkam, Gopalapuram, Guduvanchery, Guindy, Injambakkam, Irumbuliyur, Iyyappanthangal, Jafferkhanpet, Jalladianpet, Kanathur, Kanchipuram, Kandhanchavadi, Kandigai, Karapakkam, Kasturbai Nagar, Kattankulathur, Kattupakkam, Kazhipattur, Keelkattalai, Kelambakkam, Kilpauk, KK Nagar, Kodambakkam, Kolapakkam, Kolathur, Kottivakkam, Kotturpuram, Kovalam, Kovilambakkam, Kovilanchery, Koyambedu, Kumananchavadi, Kundrathur, Little Mount, Madambakkam, Madhavaram, Madipakkam, Maduravoyal, Mahabalipuram, Mambakkam, Manapakkam, Mandaveli, Mangadu, Mannivakkam, Maraimalai Nagar, Medavakkam, Meenambakkam, Mogappair, Moolakadai, Moulivakkam, Mount Road, MRC Nagar, Mudichur, Mugalivakkam, Muttukadu, Mylapore, Nandambakkam, Nandanam, Nanganallur, Nanmangalam, Narayanapuram, Navalur, Neelankarai, Nesapakkam, Nolambur, Nungambakkam, OMR, Oragadam, Ottiyambakkam, Padappai, Padi, Padur, Palavakkam, Pallavan Salai, Pallavaram, Pallikaranai, Pammal, Parangimalai, Paruthipattu, Pazhavanthangal, Perambur, Perumbakkam, Perungudi, Polichalur, Pondy Bazaar, Ponmar, Poonamallee, Porur, Pudupakkam, Pudupet, Purasaiwakkam, Puzhuthivakkam, RA Puram, Rajakilpakkam, Ramapuram, Red Hills, Royapettah, Saidapet, Saidapet East, Saligramam, Sanatorium, Santhome, Santhosapuram, Selaiyur, Sembakkam, Semmanjeri, Shenoy Nagar, Sholinganallur, Singaperumal Koil, Siruseri, Sithalapakkam, Srinivasa Nagar, St Thomas Mount, T Nagar, Tambaram, Tambaram East, Taramani, Teynampet, Thalambur, Thirumangalam, Thirumazhisai, Thiruneermalai, Thiruvallur, Thiruvanmiyur, Thiruverkadu, Thiruvottiyur, Thoraipakkam, Thousand Light, Tidel Park, Tiruvallur, Triplicane, TTK Road, Ullagaram, Urapakkam, Uthandi, Vadapalani, Vadapalani East, Valasaravakkam, Vallalar Nagar, Valluvar Kottam, Vanagaram, Vandalur, Vasanta Nagar, Velachery, Vengaivasal, Vepery, Vettuvankeni, Vijaya Nagar, Villivakkam, Virugambakkam, West Mambalam, West Saidapet
FITA Velachery or T Nagar or Thoraipakkam OMR or Anna Nagar or Tambaram or Porur or Pallikaranai branch is just few kilometre away from your location. If you need the best training in Chennai, driving a couple of extra kilometres is worth it!
© 2024 FITA. All rights Reserved.