
Hadoop is a popular open source software for dealing with big data. It is composed of several tools, including the Hadoop Distributed File System (HDFS), MapReduce, and Apache Pig. These tools allow users to process large data sets quickly and easily. Hadoop can be used to crunch big data from a variety of sources, such as online databases, social media, and sensor data.
The Apache Foundation hosts the Hadoop codebase, while many companies offer proprietary versions of the technology. For example, Amazon Web Services offers a version called Elastic MapReduce.
Hadoop is used to support advanced analytics initiatives such as predictive analytics, data mining, and machine learning applications. These use cases require access to terabytes of data, which are processed by hundreds or thousands of nodes, each running multiple processes simultaneously. This requires sophisticated techniques to manage the resources required to process massive quantities of data efficiently. So learning the techniques from the best Hadoop Training in Chennai will lead you to a successful career in the field of Hadoop.
In addition to storing and managing data, Hadoop also supports scalable computing frameworks that enable developers to run complex algorithms without having to worry about scaling up the infrastructure.
Introduction To Data Crunching
Data crunching is a process where you take raw data and turn it into something meaningful. It involves collecting data, organizing it, analyzing it, and presenting it in a way that makes sense to people. It is a very important part of the Information Science course, because it teaches students how to analyze large amounts of data and use it to solve problems.
Data crunching is often done by scientists, engineers, statisticians, and researchers. They use data crunching techniques to help answer questions about the world around us. For example, data crunching could tell you how many miles each person drives per year, what kinds of cars people buy, and how much money people spend on gas every month. These numbers might be interesting to know, but they don’t really give you anything useful unless you can put them together to draw conclusions.
Best Hadoop Tools that Aid in Big Data Crunching & Management
Hadoop plays a significant part in Big Data management. This open source framework is used to store a vast amount of information across multiple servers. With the help of Hadoop you can easily process large volumes of data. There are many tools that aid in Big Data crunching and management. Hadoop ecosystem components include Pig, Hive, MapReduce, Zookeeper, Oozie, Yarn, Flume, Sqoop etc. Let’s now take a look at some of the best Hadoop tools for Big Data management.
Hadoop Ecosystem
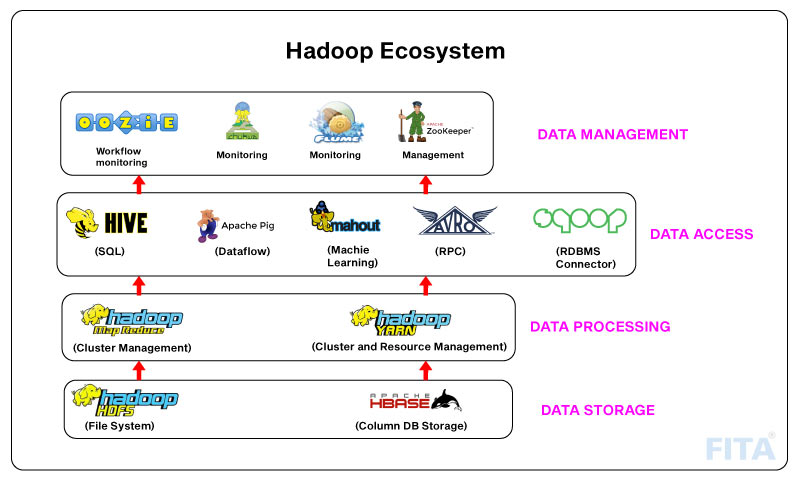
FITA Academy helps you upskill to the best of your capabilities by providing you with Hadoop Training In Bangalore. Hadoop ecosystem in big data platform that offers distributed storage and processing capabilities. It can be used to crunch big data using various Hadoop tools.
Hadoop Distributed File System
HDFS is one of the most important components of Hadoop. It is a distributed file system designed to store very large files on commodity servers. The main advantage of using HDFS is that it can be scaled horizontally (i.e., more machines added) rather than vertically (more storage space). In other words, you don’t need to buy additional hard drives to expand your cluster size. You just add more machines.
Some features of Hadoop Distributed File System are
Distributed Architecture: HDFS uses a client/server architecture where clients request services from the server. A single master node controls all operations. All data is stored redundantly across three data nodes.
High Availability: If any data node fails, another data node will take over its responsibilities.
Scalability: HDFS scales well with an increasing number of nodes.
Consistency: HDFS guarantees consistency between replicas.
Fault Tolerance: HDFS has built-in mechanisms to detect and recover from failures.
High Performance: HDFS achieves high throughput due to parallelism and caching.
Security: HDFS includes security features like encryption and authentication.
The Two core components HDFS are
NameNode & Datanode:
Name Node: It stores metadata information about the cluster and keeps track of the location of every block of data.
Datanodes: They store blocks of data and provide them to the Name Node when requested.
Hbase
HBase is a columnar database management system based on Google’s BigTable design. It was originally created by LinkedIn but later acquired by Yahoo! Inc. and then sold to the Apache Software Foundation.
HBase is a NoSQL database that runs on top of Hadoop. Like traditional databases, HBase allows users to query and update rows of data. But unlike traditional databases, HBase does not enforce row-level locking. Instead, it provides strong consistency at the column level.
The basic idea behind HBase is to organize data into tables, called regions, and columns within those tables. Each region contains a set of cells, and each cell holds a value. Cells are organized into columns, and columns hold values.
Some features of Hbase are
Column Family: Column families allow multiple columns to share a common name. This makes it easier to understand what data is stored in which column.
Row Level Locking: Row level locking ensures that only one user or process can access a given row at a time.
Strong Consistency: HBase provides strong consistency among different copies of the same row.
Fast Queries: HBasesupports fast queries through MapReduce.
High Throughput: HBase achieves high throughput because of its use of disk caching.
Security: HBase includes security features such as encryption and authentication.
Apache Mahout
Mahout is an open source machine learning library written in Java. It is used for developing applications that perform classification, clustering, recommendation, and visualization tasks.
It is part of the Apache Hadoop ecosystem and is developed by the Apache Software Foundation. It consists of several libraries including Mahout, MLLib, Algorithms, and others.
Some features of Apache Mahout are
Machine Learning: Mahout simple API enables developers to easily build machine learning algorithms using simple programming models.
Data Mining: Mahout supports many popular data mining techniques including k-means, hierarchical clustering, and decision trees.
Clustering: Mahout offers a variety of clustering algorithms including DBSCAN, KMeans, and EM.
Recommender Systems: Mahout suggests methods for building recommender systems.
Visualization: Mahout Support The creation of visualizations from data sets.
Apache Mahout is a powerful tool that can be used to process large data sets. It can be used to find patterns and insights in data, and can be deployed on a wide range of platforms. To become an efficient developer with Big Data Training in Coimbatore in a scalable way to process large data sets and making it a valuable tool for businesses of all sizes.
Hive
Hive is a distributed SQL engine designed to run over HDFS. It was initially developed by Facebook and released under the Apache License 2.0.
Hiveql language is similar to standard SQL, with some extensions. The most important extension is support for mapreduce operations.
Hivesql is also compatible with other languages like Pig Latin and Python.
Hive is built on top of Hadoop’s Distributed File System (HDFS) and uses the Map Reduce framework.
Some features of Hive are
Distributed Storage: Hive stores all data in HDFS.
Map Reduce: Hive uses MapReduce to execute queries.
Query Language: Hive has a SQL-like syntax.
Integration with Other Technologies: Hive integrates well with other technologies such as Pig, HiveQL, and Spark.
Support for Multiple Languages: Hive supports multiple languages such as SQL, Pig, and Python.
Support for Large Datasets: Hive supports large datasets.
Pig
Pig is a declarative language for writing data analysis programs. It is based on the concept of scripts. Scripts consist of statements that define how data should be processed.
The main advantage of Pig is that it allows users to write their own functions without having to learn a new programming language.
The Pig script can be executed either directly or via MapReduce jobs.
Some of the features are
Declarative Programming: Pigis a declarative language. This means that you do not need to specify what steps to take but instead describe what results you want.
Scripting: Pig Script is similar to a shell scripting language.
Execution Model: Pig Can be executed both directly and via MapReduce.
Language Integration: Pig Integrates well with other languages such as Java, Ruby, C++, and Perl.
Large Scale Processing: Pig Supports large scale processing.
Sqoop
Sqoop is a tool for transferring data from one database to another. It is used to import data into Hadoop.
It is used to transfer data from relational databases to Hadoop.
Sqoop is a command line utility that runs on Linux/Unix systems.
Some of the features of Sqoop are
Import: Sqoop imports data from various sources including MySQL, CSV files, PostgreSQL, Microsoft Access, ODBC,Oracle, and JDBC.
Export: Sqoop exports data to various formats including MySQL, Oracle, and CSV.
Hue
Hue is a web interface for managing Hadoop clusters. It is designed to make it easier to use Hadoop clusters.
Hue is a web application that runs on Tomcat servers.
Some of the features of Hue are
Web Interface: Hue provides a Web-based user interface for managing Hadoops.
Administration Console: Hue offers a console for managing Hadoop resources.
ZooKeeper
ZooKeeper is a centralized service for maintaining configuration information across multiple machines.
It is a distributed coordination service that helps applications coordinate actions among themselves.
Zookeeper is a networked distributed file system. It is used to store configurations and maintain state information about nodes in a cluster.
Some of the features of ZooKeeper are
Distributed Consensus: Zookeeper provides a consensus mechanism for ensuring that all clients see the same view of the world.
High Availability: Zookeeper can automatically failover to a new server if a node fails.
Why Need of Data Crunching Techniques
Data crunching techniques can save time, money, and effort. They can help us to reduce the number of variables we must deal with, because they allow us to focus our attention on what matters. We can use data crunching techniques to analyze large amounts of information quickly and efficiently. Join the Data Analytics Course in Chennai to master the data crunching techniques and gain the skills needed for effective data analytics.
When we want to find out how much something costs or where we can buy something cheap, we usually look up prices online. But what if you wanted to know how much it cost to buy everything in a store, including the price per item, without having to go around looking for each price tag yourself? This is where data crunching comes in handy.
You could write down every single price tag and total it up later. Or you could take photos of each price tag and add them together. This method works, but it takes a long time. And even though you might be able to do this manually, it would probably take hours.
Instead, you can use data crunching to calculate the total cost of buying everything in the store. For example, you can open a spreadsheet document, enter each individual price, and sum it up. Then you can repeat this step for every product you want to include. In seconds, you’ll have the answer to your question. Finally if you require an in -depth understanding where you will get all the required information, then you can enroll in our Big Data Online Course for getting all the details of your data.
End Summary
Using Hadoop tools to crunch Big Data can be a powerful way to get a quick understanding of data. Hadoop is an open source platform that can be used by anyone with the necessary skills, so the potential for using it to solve business problems is vast. Additionally, since Hadoop is scalable and easy to use, businesses don’t need to have a large investment in infrastructure to start using it. Organizations should consider using Hadoop to solve their big data challenges, and learn about the various tools and platforms available in the Hadoop ecosystem.
