
In a rapidly evolving world where automation is taking over most manual tasks, the definition of “manual” is undergoing a transformation. With the development of various types of machine learning algorithms, computers are now capable of playing chess, performing surgeries, and becoming more intelligent and personalized.
The current era is characterized by continuous technological advancements, and by examining the progress of computing over the years, we can make predictions about what lies ahead. One notable aspect of this revolution is the democratization of computing tools and techniques. In the past five years, data scientists have constructed sophisticated machines for data analysis, seamlessly executing advanced techniques and yielding remarkable results.
If you have a comprehensive understanding of machine learning, you can join Machine Learning Course in Chennai, which will help you have a better understanding of machine learning algorithms, types of machine learning algorithms, use of algorithms, how to learn algorithms, machine learning basic concepts and algorithm techniques.
These dynamic times have given rise to a wide range of machine-learning algorithms specifically designed to address complex real-world problems. These algorithms are automated and capable of self-modification, continually improving their performance over time. Before exploring the top 10 machine learning algorithms that are essential to know, let’s first understand the several categories that machine learning algorithms fall into
Types of Machine Learning Algorithms
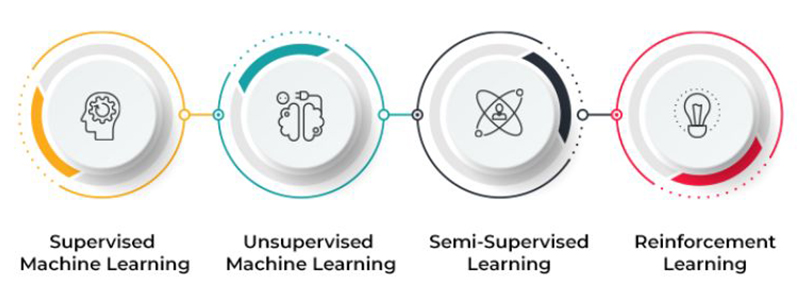
Four categories of machine learning algorithms are recognised:
- Supervised
- Unsupervised Learning
- Semi-supervised Learning
- Reinforcement Learning
Supervised Learning
A machine learning strategy called supervised learning which involves algorithms learning from labelled data. In this approach, the algorithm is provided with input data along with corresponding correct output labels. The goal is to train the algorithm to accurately predict labels for new and unseen data. The supervised learning algorithms Decision Trees, Support Vector Machines, Random Forests, and Naive Bayes are well-known examples of. These procedures are employed for tasks such as classification, regression, and time series forecasting. Supervised learning finds wide applications across various domains, including healthcare, finance, marketing, and image recognition, enabling predictions and valuable insights to be derived from data.
Unsupervised Learning
In this approach to machine learning, algorithms are utilized to analyze unlabeled data that lacks predefined output labels. The primary goal is to identify patterns, relationships, or structures within the data. Unlike supervised learning, unsupervised learning algorithms operate independently to unveil hidden insights and group similar data points together. Dimensionality reduction methods, K-means, hierarchical clustering, and DBSCAN are examples of clustering algorithms., are well-known unsupervised learning approaches. such as PCA and t-SNE. Unsupervised learning proves valuable in tasks such as customer segmentation, anomaly detection, and data exploration.
Semi-supervised Learning
Semi-supervised learning is a hybrid approach in machine learning that combines both labelled and unlabeled data during the training phase. By utilizing a smaller set of labelled data along with a larger set of unlabeled data, the learning process is enhanced. The incorporation of unlabeled data provides additional information and context to improve the model’s understanding and performance. This approach overcomes the limitations of relying solely on labelled data. Semi-supervised learning proves particularly valuable in situations where acquiring labelled data is costly or time-consuming. It can be applied to various tasks, including classification, regression, and anomaly detection, enabling models to make more accurate predictions and achieve better generalization in real-world scenarios.
Reinforcement Learning
A machine learning algorithm called reinforcement learning which draws inspiration from human learning through trial and error. In this approach, An agent interacts with its surroundings and gains the ability to choose the best course of action to maximise cumulative rewards. Feedback in the form of rewards or penalties is provided to the agent based on its actions. Over time, the agent learns to take actions that yield the most favourable outcomes. Reinforcement learning finds applications in areas such as robotics, game-playing, and autonomous systems. It enables robots to draw lessons from their past, adjust to shifting circumstances, and accomplish long-term objectives by taking a sequence of actions. This dynamic learning approach makes reinforcement learning a powerful technique for addressing complex decision-making problems.
Join the Python Course in Bangalore at FITA Academy, which has been scrupulously designed for the bangalore-based student who intends to begin their career as a Python developer.
What are the 10 Popular Machine Learning Algorithms?
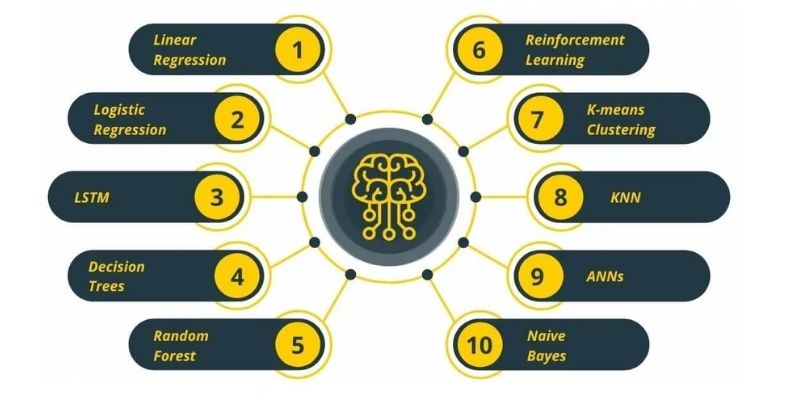
Below is the list of the Top 10 commonly used Machine Learning (ML) Algorithms:
- Linear regression
- Logistic regression
- Decision tree
- SVM algorithm
- Naive Bayes algorithm
- KNN algorithm
- K-means
- Random forest algorithm
- Dimensionality reduction algorithms
- Gradient boosting algorithm and AdaBoosting algorithm
How Learning These Vital Algorithms Can Improve Your Skills in Machine Learning
If you have an interest in data science or machine learning, you can utilize these methods to develop practical machine-learning projects.
The list of 10 common machine learning algorithms comprises three widely recognized types: supervised learning, unsupervised learning, and reinforcement learning. These techniques are extensively employed in the field of machine learning.
If you want to know more about the latest salary trends for Machine Learning Engineer, Check out Machine Learning Engineer Salary for Freshers, which will help you get an insight into the packages as per the companies, skills and experience.
1. Linear Regression
To grasp the functionality of Linear Regression, let’s imagine arranging random logs of wood in increasing order of their weight. However, there’s a twist – you can’t directly weigh each log. Instead, you have to estimate their weight by visually analyzing their height and girth and arranging them based on a combination of these observable parameters. This analogy illustrates the essence of linear regression in machine learning.
By fitting the independent and dependent variables into a line, a relationship between them is created. This phrase is referred to a linear equation that serves as a representation of the regression line.
Y = a * X + b;
In this equation:
Y represents the dependent variable,
a denotes the slope,
X represents the independent variable, and
b represents the intercept.
The coefficients a and b are derived through the reduction of the total squared deviation between the data points and the regression line.
2. Logistic Regression
Logistic regression is a statistical method of techinique used to estimate discrete values, typically binary values like 0 or 1, based on a set of independent variables. It is commonly employedby fitting the data to a logit function, one may anticipate the likelihood of an event. Logistic regression is also referred to as logit regression.
To enhance logistic regression models, several methods are frequently utilized:
- Incorporating interaction terms: This involves including interaction effects between variables to capture potential relationships and improve the model’s predictive power.
- Feature selection: Eliminating certain features or variables that may not contribute significantly to the model’s performance can help simplify and improve the logistic regression model.
- Regularization techniques: Applying regularization methods, such as L1 or L2 regularization, helps prevent overfitting and improves the model’s generalization ability.
- Non-linear models: In some cases, using non-linear models, such as polynomial regression or spline regression, can capture more complex relationships between variables and enhance the logistic regression model’s accuracy and flexibility.
3. Decision Tree
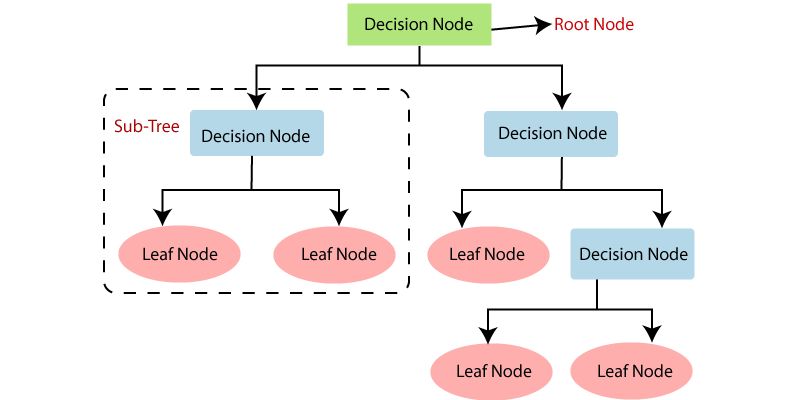
The Decision Tree algorithm is widely recognized and extensively used in machine learning. It is a supervised learning algorithm primarily utilized for classification tasks. Decision Trees are effective in handling both categorical and continuous dependent variables. This algorithm partitions the population into multiple homogeneous sets by considering the most significant attributes or independent variables.
4. SVM (Support Vector Machine) Algorithm
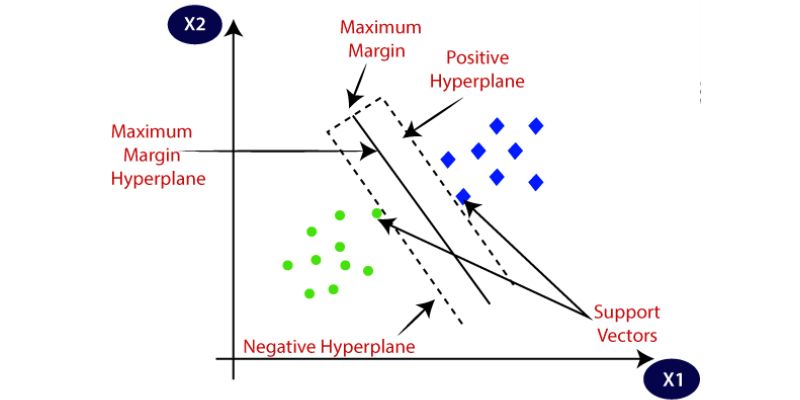
The SVM (Support Vector Machine) algorithm is a classification method that involves representing raw data as points in an n-dimensional space, where the number of dimensions corresponds to the number of features. Each feature value is associated with a specific coordinate, enabling easy data classification. Classifiers, represented as lines, can be employed to separate and visualize the data on a graph.
5. Naive Bayes Algorithm
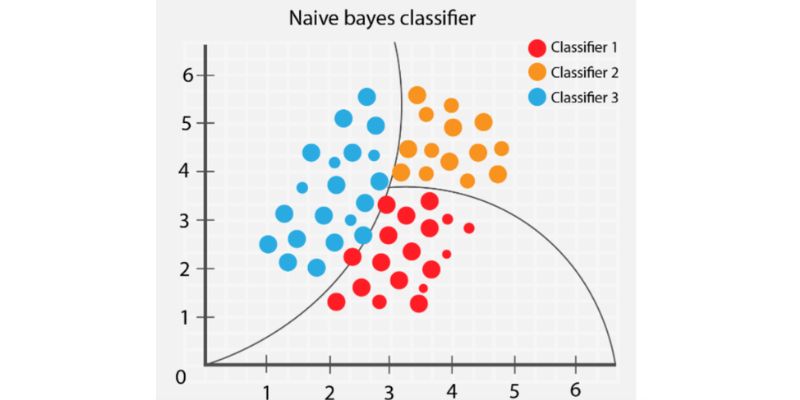
The Naive Bayes classifier operates under the assumption that the presence of a specific feature in a class is independent of the presence of any other feature.
Even if there are correlations between these features, a Naive Bayes classifier treats each feature as independent when calculating the probability of a particular outcome.
A Naive Bayesian model is straightforward to construct and particularly advantageous for large datasets. It is a simple yet powerful method known to outperform even complex classification techniques.
If you want to become a Python Developer, you can join a Python Course in Coimbatore, which will help you have a profound understanding of Data, Problems, tools, Linear Classification, and Python algorithms.
6. KNN (K- Nearest Neighbors) Algorithm
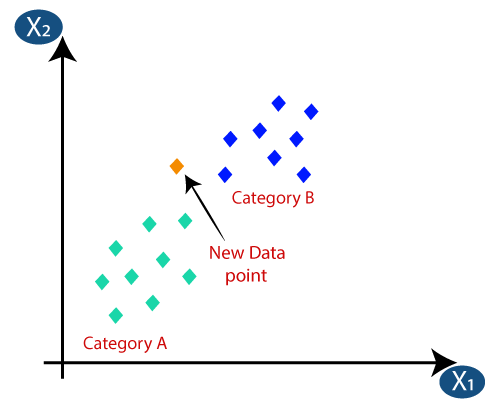
The K Nearest Neighbors (KNN) algorithm can be applied to both classification and regression problems, although it is more commonly used for solving classification tasks within the Data Science industry. It is a straightforward algorithm that catalogues all examples currently accessible and sorts new cases according to a majority vote of their k nearest neighbours. The algorithm assigns the case to the class that it has the most similarities with, using a distance function to measure the similarity.
KNN can be easily understood by drawing a parallel to real-life scenarios. For instance, when seeking information about a person, it is logical to consult their friends and colleagues.
Before selecting the K Nearest Neighbors algorithm, several factors should be considered:
- Computational complexity: KNN can be computationally expensive, especially with larger datasets, which should be taken into account.
- Variable normalization: It is advisable to normalize the variables as higher range variables can potentially bias the algorithm’s results.
- Data pre-processing: Despite the simplicity of KNN, data pre-processing steps such as handling missing values, outlier removal, and feature scaling are still necessary to ensure reliable results.
7. K-Means
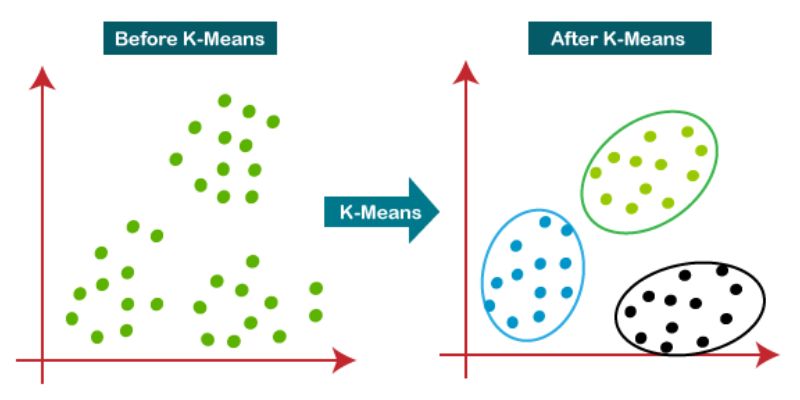
K-means is an unsupervised learning algorithm utilized for clustering tasks. It groups datasets into a specific number of clusters (referred to as K), ensuring that data points within each cluster exhibit similarity while being dissimilar to data points in other clusters.
The process of forming clusters in K-means involves the following steps:
- The algorithm initially selects K centroids, representing the centre points of the clusters.
- Each data point is assigned to the cluster with the closest centroid, resulting in the formation of K clusters.
- New centroids are computed based on the members within each cluster.
- Using these updated centroids, the algorithm calculates the closest distance between each data point and the centroids. This step is repeated until the centroids no longer change significantly, indicating convergence and the formation of stable clusters.
8. Random Forest Algorithm
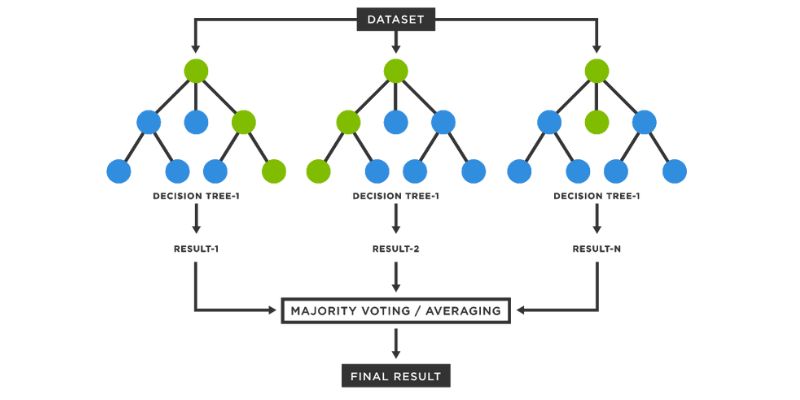
Decision trees are assembled into a Random Forest working together. It combines the predictions of individual trees to assign a new object a class depending on its characteristics. Each tree in the forest independently classifies the object, and the final class is determined by the majority vote of all the trees.
Here is how each tree is grown within a Random Forest:
- For growing a tree, a random sample of N cases is taken from the training set, where N represents the total number of cases. This sample serves as the training set for that particular tree.
- If there are M input variables, a value m<<M is chosen. At the end of each node of the tree, m variables are randomly selected from the M variables, and the best split based on the m variables is used to divide the node.
- The tree is grown to its maximum potential without any pruning or trimming.
- By combining the predictions from multiple trees, Random Forests can provide robust and accurate classifications.
9. Dimensionality Reduction Algorithms
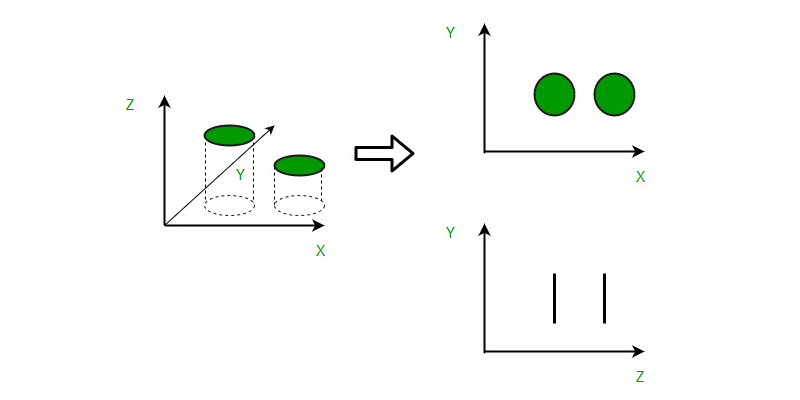
In the present era, various organizations accumulate and analyze massive volumes of data. As a data scientist, you understand that within this raw data lies valuable information. The task at hand is to extract meaningful patterns and variables.
To address this challenge, dimensionality reduction algorithms such as Decision Trees, Factor Analysis, Missing Value Ratios, and Random Forest. These algorithms aid in uncovering pertinent insights and details within the data.
10. Gradient Boosting Algorithm and AdaBoosting Algorithm
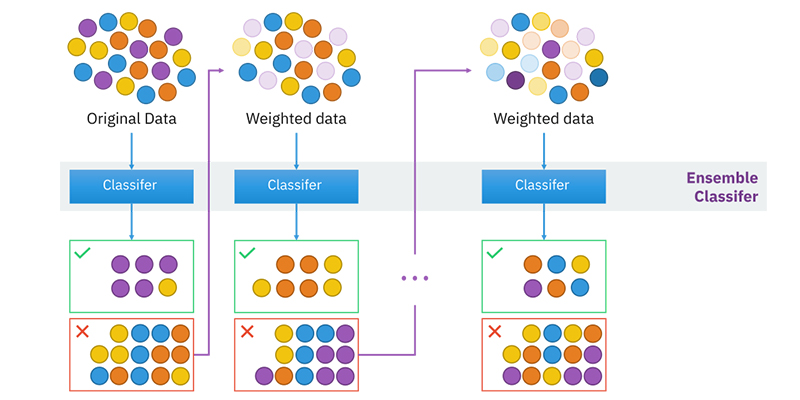
Gradient Boosting Algorithm and AdaBoosting Algorithm are popular boosting algorithms utilized for accurate prediction when dealing with large datasets. Boosting is an ensemble learning technique that combines the predictive capabilities of multiple base estimators to enhance overall performance and robustness.
In essence, boosting combines numerous weak or average predictors to create a powerful predictor. These boosting algorithms have demonstrated effectiveness in various data science competitions like Kaggle, AV Hackathon, and CrowdAnalytix. They are widely favoured in the field of machine learning today. To achieve accurate results, these algorithms can be implemented using Python and R programming languages.
Now that you have understood machine learning algorithms, types of machine learning algorithms, how to learn algorithms, machine learning basic concepts and algorithm techniques. So, if you want to become a machine learning engineer, you can join a Machine Learning Course in Coimbatore and learn classification errors, regularization, Logistic Regression, Linear regression, estimator bias, and Kernel regression.
